| **Model Name** | **temperature** | **top_p** |
|---|---|---|
| `mimo-v2.5-pro` `mimo-v2-pro` |
|
|
| `mimo-v2.5` `mimo-v2-omni` |
|
|
| `mimo-v2.5-tts` `mimo-v2.5-tts-voicedesign` `mimo-v2.5-tts-voiceclone` `mimo-v2-tts` |
|
|
| `mimo-v2-flash` |
|
|
| **Task Type** | **temperature** | **top_p** |
|---|---|---|
| Vibe Coding | 0.3 | 0.95 |
| Function Call | 0.3 | 0.95 |
| General Conversation | 0.8 | 0.95 |
| Creative Writing | 0.8 | 0.95 |
| WebDev | 0.8 | 0.95 |
| Mathematical Reasoning | 1 | 0.95 |
| **Error Code** | **Causes** | **Solutions** |
|---|---|---|
| 400 - Invalid Format | Invalid request format |
|
| 401 - Authentication Fails |
|
|
| 402 - Insufficient Balance | Insufficient account balance | Check your account balance and recharge in a timely manner |
| 403 - Forbidden Access | The service is currently not available in the current region, or the API Key has been restricted by risk control | Create a new API Key and pay attention to the security of input content |
| 404 - Not Found | The requested endpoint or model does not support image input capability | Verify that the model / endpoint being used supports image input capability |
| 421 - Content Filter | Content moderation and blocking | Avoid entering unsafe or sensitive content |
| 429 - Too Many Requests | Requests are too frequent, or the quota of Token Plan has been exhausted |
|
| 500 - Server Error | Our server encounters an issue | Please try again later, or contact us for resolution |
| 503 - Server Overloaded | The server is overloaded due to high traffic | Please try again later |
| Input ≤ 256K | Input 256K - 1M | |||||
|---|---|---|---|---|---|---|
| Input (Cache Hit) | Input (Cache Miss) | Output | Input (Cache Hit) | Input (Cache Miss) | Output | |
| `mimo-v2.5-pro` `mimo-v2-pro` |
¥1.40 | ¥7.00 | ¥21.00 | ¥2.80 | ¥14.00 | ¥42.00 |
| `mimo-v2.5` | ¥0.56 | ¥2.80 | ¥14.00 | ¥1.12 | ¥5.60 | ¥28.00 |
| `mimo-v2-omni` | ¥0.56 | ¥2.80 | ¥14.00 | — | — | — |
| `mimo-v2-flash` | ¥0.07 | ¥0.70 | ¥2.10 | — | — | — |
| `mimo-v2.5-tts` `mimo-v2.5-tts-voiceclone` `mimo-v2.5-tts-voicedesign` `mimo-v2-tts` |
Limited-time free | |||||
| Input ≤ 256K | Input 256K - 1M | |||||
|---|---|---|---|---|---|---|
| Input (Cache Hit) | Input (Cache Miss) | Output | Input (Cache Hit) | Input (Cache Miss) | Output | |
| `mimo-v2.5-pro` `mimo-v2-pro` |
$0.20 | $1.00 | $3.00 | $0.40 | $2.00 | $6.00 |
| `mimo-v2.5` | $0.08 | $0.40 | $2.00 | $0.16 | $0.80 | $4.00 |
| `mimo-v2-omni` | $0.08 | $0.40 | $2.00 | — | — | — |
| `mimo-v2-flash` | $0.01 | $0.10 | $0.30 | — | — | — |
| `mimo-v2.5-tts` `mimo-v2.5-tts-voiceclone` `mimo-v2.5-tts-voicedesign` `mimo-v2-tts` |
Limited-time free | |||||
| Service Item | Price | Description |
|---|---|---|
| Domestic Internet Connectivity Service | ¥25 / 1000 times | Includes web search and web parsing, used for domestic regional networked search of relevant content |
| Overseas Internet Connectivity Service | $5 / 1000 times | Includes web search and web parsing, used for networked search of relevant content in overseas regions |
| **Model Name** | `mimo-v2.5-pro`, `mimo-v2-pro` |
|---|---|
| **Category** | Text Generation - General Large Language Model |
| **Context Length** | 1 M |
| **Maximum Output Length** | 128 K |
| **Model Capability** | Text generation, deep thinking, streaming output, function call, structured output, internet search |
| **Flow Control** | RPM: 100 TPM: 10 M |
| **Model Name** | `mimo-v2.5` | `mimo-v2-omni` |
|---|---|---|
| **Category** | Text Generation - Full Modal Understanding Model | Text Generation - Full Modal Understanding Model |
| **Context Length** | 1 M | 256 K |
| **Maximum Output Length** | 128 K | 128 K |
| **Model Capability** | Full-modal understanding, in-depth thinking, streaming output, function call, structured output, and internet search | |
| **Flow Control** | RPM: 100 TPM: 10 M |
|
| **Model Name** | `mimo-v2.5-tts` | `mimo-v2.5-tts-voiceclone` | `mimo-v2.5-tts-voicedesign` | `mimo-v2-tts` |
|---|---|---|---|---|
| **Category** | Speech Synthesis Model | Speech Synthesis Model | Speech Synthesis Model | Speech Synthesis Model |
| **Context Length** | 8 K | 8 K | 8 K | 8 K |
| **Maximum Output Length** | 8 K | 8 K | 8 K | 8 K |
| **Model Capability** | Speech Synthesis | Timbre Cloning | Timbre Design | Speech Synthesis |
| **Flow Control** | RPM: 100 TPM: 10 M |
|||
| **Model Name** | `mimo-v2-flash` |
|---|---|
| **Category** | Text Generation - General Large Language Model |
| **Context Length** | 256 K |
| **Maximum Output Length** | 64 K |
| **Model Capability** | Text generation, deep thinking, streaming output, function call, structured output, internet search |
| **Flow Control** | RPM: 100 TPM: 10 M |
|  |  |  |  |
|---|
 Speech technology is undergoing such a transformation: from "being able to listen and read" to "precise understanding and flexible expression". In real creative and interactive scenarios, machines not only need to penetrate complex spoken language environments - dialect accents, environmental noise, multiple people speaking simultaneously - but also use voice to shape characters, grasp emotions, so that expression is no longer just about conveying words, but also conveying feelings.
Whether it's content creators or businesses relying on speech technology, what they truly need is a speech system that can be freely controlled by language: input a noisy meeting recording, and it can accurately transcribe; input a director's note saying "this part should be low and angry", and it can generate a fitting performance. It understands everything and can express everything.
To this end, we officially release today **MiMo-V2.5-TTS Series** and **MiMo-V2.5-ASR** — a whole-link speech model series for the Agent era, covering the two core capabilities of recognition and synthesis, enabling both speech input and output to be freely scheduled by language.
- The MiMo-V2.5-TTS Series includes three models, which have now been launched on **Xiaomi MiMo Open Platform** , and **are available for free for a limited time** . The three models share unified style instruction following, audio label control, and text understanding capabilities, enabling voice performance to be precisely regulated by language, respectively covering three typical creative needs:
- **MiMo-V2.5-TTS:** Built-in with multiple high-quality premium voices, supports fine-grained control over speech rate, emotion, tone, etc., Out Of The Box, meeting multi-scenario expression needs.
- **MiMo-V2.5-TTS-VoiceDesign:** Quickly define and generate a brand-new voice in one sentence, making voice creation more intuitive and efficient.
- **MiMo-V2.5-TTS-VoiceClone:** High-fidelity replication of target timbre with a small number of samples, while maintaining stable style instruction following and audio label control capabilities.
**MiMo-Studio Quick Experience Address:** **https://aistudio.xiaomimimo.com/#/c**
- **MiMo-V2.5-ASR is officially open-sourced.** The model's speech recognition performance in complex real-world scenarios such as Chinese-English bilingual, Chinese dialects, Code-Switch, strong noise, and multi-speaker has reached the industry-leading level, providing clear and reliable speech transcription for Agents and ensuring that every interaction is based on accurate understanding.
## MiMo-V2.5-TTS: Let Voice Become Everyone's Creativity
### Core Features of TTS Series
#### Precise ability to follow style instructions
From short single-sentence instructions to an entire director's notes, the model can consistently understand and follow them, covering multiple dimensions such as emotion, tone, speaking speed, vocalization style, and language style. Instructions do not need to be written as structured parameters - simply describe the desired feeling as if giving a briefing to an actor, and the model will translate it into the corresponding performance.
For scenarios with higher consistency requirements - such as audio dramas, game NPCs, and character-based dialogues - the model also supports **director script-level** structured input: **characters** , **scenes** , **detailed instructions** are described in layers, with each layer independently updated at its own pace and freely combined. This layering not only ensures that the timbre identity of the character remains consistent throughout, but also allows the performance of each sentence to be individually controlled.
**Case1**
Instruct :
声音低沉沙哑一点,像个历经沧桑的老前辈在讲述传奇人物。语气里带点由衷的敬佩,娓娓道来。
Text:
街口那个老周啊,媳妇走得早,一个人拉扯俩娃,白天蹬三轮,晚上还去夜市摆摊修鞋。现在俩孩子都有出息喽,想接他去城里享福——他不去,就守着那间小铺子。哎,人哪,骨头硬,心里头就踏实。
Audio(Voice name:冰糖):
Speech technology is undergoing such a transformation: from "being able to listen and read" to "precise understanding and flexible expression". In real creative and interactive scenarios, machines not only need to penetrate complex spoken language environments - dialect accents, environmental noise, multiple people speaking simultaneously - but also use voice to shape characters, grasp emotions, so that expression is no longer just about conveying words, but also conveying feelings.
Whether it's content creators or businesses relying on speech technology, what they truly need is a speech system that can be freely controlled by language: input a noisy meeting recording, and it can accurately transcribe; input a director's note saying "this part should be low and angry", and it can generate a fitting performance. It understands everything and can express everything.
To this end, we officially release today **MiMo-V2.5-TTS Series** and **MiMo-V2.5-ASR** — a whole-link speech model series for the Agent era, covering the two core capabilities of recognition and synthesis, enabling both speech input and output to be freely scheduled by language.
- The MiMo-V2.5-TTS Series includes three models, which have now been launched on **Xiaomi MiMo Open Platform** , and **are available for free for a limited time** . The three models share unified style instruction following, audio label control, and text understanding capabilities, enabling voice performance to be precisely regulated by language, respectively covering three typical creative needs:
- **MiMo-V2.5-TTS:** Built-in with multiple high-quality premium voices, supports fine-grained control over speech rate, emotion, tone, etc., Out Of The Box, meeting multi-scenario expression needs.
- **MiMo-V2.5-TTS-VoiceDesign:** Quickly define and generate a brand-new voice in one sentence, making voice creation more intuitive and efficient.
- **MiMo-V2.5-TTS-VoiceClone:** High-fidelity replication of target timbre with a small number of samples, while maintaining stable style instruction following and audio label control capabilities.
**MiMo-Studio Quick Experience Address:** **https://aistudio.xiaomimimo.com/#/c**
- **MiMo-V2.5-ASR is officially open-sourced.** The model's speech recognition performance in complex real-world scenarios such as Chinese-English bilingual, Chinese dialects, Code-Switch, strong noise, and multi-speaker has reached the industry-leading level, providing clear and reliable speech transcription for Agents and ensuring that every interaction is based on accurate understanding.
## MiMo-V2.5-TTS: Let Voice Become Everyone's Creativity
### Core Features of TTS Series
#### Precise ability to follow style instructions
From short single-sentence instructions to an entire director's notes, the model can consistently understand and follow them, covering multiple dimensions such as emotion, tone, speaking speed, vocalization style, and language style. Instructions do not need to be written as structured parameters - simply describe the desired feeling as if giving a briefing to an actor, and the model will translate it into the corresponding performance.
For scenarios with higher consistency requirements - such as audio dramas, game NPCs, and character-based dialogues - the model also supports **director script-level** structured input: **characters** , **scenes** , **detailed instructions** are described in layers, with each layer independently updated at its own pace and freely combined. This layering not only ensures that the timbre identity of the character remains consistent throughout, but also allows the performance of each sentence to be individually controlled.
**Case1**
Instruct :
声音低沉沙哑一点,像个历经沧桑的老前辈在讲述传奇人物。语气里带点由衷的敬佩,娓娓道来。
Text:
街口那个老周啊,媳妇走得早,一个人拉扯俩娃,白天蹬三轮,晚上还去夜市摆摊修鞋。现在俩孩子都有出息喽,想接他去城里享福——他不去,就守着那间小铺子。哎,人哪,骨头硬,心里头就踏实。
Audio(Voice name:冰糖):
 #### MiMo-V2.5-TTS-VoiceDesign
The timbre design is aimed at scenarios where " **I have a voice in my heart, but the world doesn't have one yet** ": game NPCs, animated characters, virtual LIVE creators, brand IPs, atypical voices of audio dramas - these are difficult to choose directly from the timbre library and are not suitable for human cloning.
This model supports **generating a brand new timbre from scratch through natural language descriptions** , without the need for any reference audio. Users can freely use any descriptive dimensions such as age, gender, accent, timbre, vocalization style, personality, etc. - for example, "an elderly Eastern European scholar, with a deep, slightly hoarse voice and a slow speaking rhythm" or "a vibrant young girl, with a clear voice and a slight upward inflection at the end of sentences" - and the model can synthesize the corresponding character timbre.
Thanks to large-scale pre-training, the model can also reasonably interpret **complex, ambiguous, or even contradictory** descriptions, rather than being limited to coarse-grained labels such as "male/female/young/old". This enables timbre design not only to generate unique voices that are difficult for real people to provide, but also to accurately reproduce the voice lines of a certain type of character.
**Case1**
Instruct :
一位中年男性,说标准普通话,嗓音低沉有磁性,带有轻微的沙哑质感,像纪录片旁白解说员,沉稳而有感染力。
Text:
当最后一缕阳光消失在地平线之下,这片沉睡了亿万年的大地开始显露它真正的面貌。在这寂静的荒野中,每一块岩石都记录着时间的流逝,每一阵风都在诉说着古老的故事。
Audio:
#### MiMo-V2.5-TTS-VoiceDesign
The timbre design is aimed at scenarios where " **I have a voice in my heart, but the world doesn't have one yet** ": game NPCs, animated characters, virtual LIVE creators, brand IPs, atypical voices of audio dramas - these are difficult to choose directly from the timbre library and are not suitable for human cloning.
This model supports **generating a brand new timbre from scratch through natural language descriptions** , without the need for any reference audio. Users can freely use any descriptive dimensions such as age, gender, accent, timbre, vocalization style, personality, etc. - for example, "an elderly Eastern European scholar, with a deep, slightly hoarse voice and a slow speaking rhythm" or "a vibrant young girl, with a clear voice and a slight upward inflection at the end of sentences" - and the model can synthesize the corresponding character timbre.
Thanks to large-scale pre-training, the model can also reasonably interpret **complex, ambiguous, or even contradictory** descriptions, rather than being limited to coarse-grained labels such as "male/female/young/old". This enables timbre design not only to generate unique voices that are difficult for real people to provide, but also to accurately reproduce the voice lines of a certain type of character.
**Case1**
Instruct :
一位中年男性,说标准普通话,嗓音低沉有磁性,带有轻微的沙哑质感,像纪录片旁白解说员,沉稳而有感染力。
Text:
当最后一缕阳光消失在地平线之下,这片沉睡了亿万年的大地开始显露它真正的面貌。在这寂静的荒野中,每一块岩石都记录着时间的流逝,每一阵风都在诉说着古老的故事。
Audio:
 For Agent applications, content creation tools, conferencing systems, and voice interaction products, this is a truly verified auditory foundation in complex real-world speech.
## How to Use
### MiMo-V2.5-TTS Series
To assist developers in exploring more scenarios,**MiMo-V2.5-TTS, MiMo-V2.5-TTS-VoiceDesign, and MiMo-V2.5-TTS-VoiceClone** are all available for free on the **Xiaomi MiMo API** Open Platform **for a limited time:**
https://platform.xiaomimimo.com/docs/usage-guide/speech-synthesis-v2.5
Meanwhile, everyone is welcome to visit **Xiaomi MiMo Studio** for a quick experience:https://aistudio.xiaomimimo.com/#/c
For Agent applications, content creation tools, conferencing systems, and voice interaction products, this is a truly verified auditory foundation in complex real-world speech.
## How to Use
### MiMo-V2.5-TTS Series
To assist developers in exploring more scenarios,**MiMo-V2.5-TTS, MiMo-V2.5-TTS-VoiceDesign, and MiMo-V2.5-TTS-VoiceClone** are all available for free on the **Xiaomi MiMo API** Open Platform **for a limited time:**
https://platform.xiaomimimo.com/docs/usage-guide/speech-synthesis-v2.5
Meanwhile, everyone is welcome to visit **Xiaomi MiMo Studio** for a quick experience:https://aistudio.xiaomimimo.com/#/c
 For more cases, please refer to [https://mimo.xiaomi.com/mimo-v2-5-](https://mimo.xiaomi.com/mimo-v2-5-tts)[tts](https://mimo.xiaomi.com/mimo-v2-5-tts)
### MiMo-V2.5-ASR
**MiMo-V2.5-ASR has now open-sourced its model weights and code**, enabling developers and researchers to directly use or conduct secondary development.
> Demo page: [https://mimo.xiaomi.com/mimo-v2-5-asr](https://mimo.xiaomi.com/mimo-v2-5-asr)
>
> Project Open Source Address: [https://github.com/XiaomiMiMo/MiMo-V2.5-ASR](https://github.com/XiaomiMiMo/MiMo-V2.5-ASR)
>
> Weight Open Source Address: https://huggingface.co/XiaomiMiMo/MiMo-V2.5-ASR
>
> Huggingface space: https://huggingface.co/spaces/XiaomiMiMo/MiMo-V2.5-ASR
## Agent Tool Call Support
To facilitate everyone's quick integration of speech capabilities into Agent applications, we have fully open-sourced the access Skill for MiMo-V2.5-TTS related models. Welcome to visit the repository to pull and use:
[https://github.com/XiaomiMiMo/MiMo-Skills](https://github.com/XiaomiMiMo/MiMo-Skills)
### Sound is just the starting point
Beyond the MiMo-V2.5-TTS Series, we would like to answer a question:
What will audio creation look like when MiMo-V2.5-TTS understands "expression", MiMo-V2.5-Pro understands "planning", and MiMo-V2.5 understands "listening"?
**The answer is: a complete, closed-loop Agent-style creative chain.**
- MiMo-V2.5-Pro —— Planning and screenwriting, breaking down tasks, writing scripts, arranging rhythm, and determining the editing sequence.
- MiMo-V2.5-TTS Series —— Timbre and Creatives, Voice Design generates timbre, Voice Clone synthesizes content.
- MiMo-V2.5 —— Listening back and evaluation, checking if the character is consistent, if the rhythm is correct, and if it deviates from the user's original intention.
An example:
> Create a scene of a summer afternoon lasting about 2 minutes. Grandpa (in his 70s, with a Beijing hutong accent, hoarse voice, drawn-out speech, lowered voice when concentrating on chess, and a booming laugh with a table slap) is playing chess under a pagoda tree. A 5-year-old grandson is squatting beside, watching ants, and occasionally interrupting with childish questions (clear, with rising intonation at the end, higher when excited, and occasional unclear pronunciation). Grandpa's tone is solemn when he gets serious, but immediately softens into a laughing scold when interrupted by his grandson.
Users only provide a single sentence, and the finished product is generated automatically:
For more cases, please refer to [https://mimo.xiaomi.com/mimo-v2-5-](https://mimo.xiaomi.com/mimo-v2-5-tts)[tts](https://mimo.xiaomi.com/mimo-v2-5-tts)
### MiMo-V2.5-ASR
**MiMo-V2.5-ASR has now open-sourced its model weights and code**, enabling developers and researchers to directly use or conduct secondary development.
> Demo page: [https://mimo.xiaomi.com/mimo-v2-5-asr](https://mimo.xiaomi.com/mimo-v2-5-asr)
>
> Project Open Source Address: [https://github.com/XiaomiMiMo/MiMo-V2.5-ASR](https://github.com/XiaomiMiMo/MiMo-V2.5-ASR)
>
> Weight Open Source Address: https://huggingface.co/XiaomiMiMo/MiMo-V2.5-ASR
>
> Huggingface space: https://huggingface.co/spaces/XiaomiMiMo/MiMo-V2.5-ASR
## Agent Tool Call Support
To facilitate everyone's quick integration of speech capabilities into Agent applications, we have fully open-sourced the access Skill for MiMo-V2.5-TTS related models. Welcome to visit the repository to pull and use:
[https://github.com/XiaomiMiMo/MiMo-Skills](https://github.com/XiaomiMiMo/MiMo-Skills)
### Sound is just the starting point
Beyond the MiMo-V2.5-TTS Series, we would like to answer a question:
What will audio creation look like when MiMo-V2.5-TTS understands "expression", MiMo-V2.5-Pro understands "planning", and MiMo-V2.5 understands "listening"?
**The answer is: a complete, closed-loop Agent-style creative chain.**
- MiMo-V2.5-Pro —— Planning and screenwriting, breaking down tasks, writing scripts, arranging rhythm, and determining the editing sequence.
- MiMo-V2.5-TTS Series —— Timbre and Creatives, Voice Design generates timbre, Voice Clone synthesizes content.
- MiMo-V2.5 —— Listening back and evaluation, checking if the character is consistent, if the rhythm is correct, and if it deviates from the user's original intention.
An example:
> Create a scene of a summer afternoon lasting about 2 minutes. Grandpa (in his 70s, with a Beijing hutong accent, hoarse voice, drawn-out speech, lowered voice when concentrating on chess, and a booming laugh with a table slap) is playing chess under a pagoda tree. A 5-year-old grandson is squatting beside, watching ants, and occasionally interrupting with childish questions (clear, with rising intonation at the end, higher when excited, and occasional unclear pronunciation). Grandpa's tone is solemn when he gets serious, but immediately softens into a laughing scold when interrupted by his grandson.
Users only provide a single sentence, and the finished product is generated automatically:
 --- DOCUMENT: Xiaomi MiMo-V2.5 Series Large Model Launches Public Beta ---
URL: https://platform.xiaomimimo.com/static/docs/news/v2.5-news.md
# Xiaomi MiMo-V2.5 Series Large Model Launches Public Beta

Today, the Xiaomi MiMo-V2.5 series of models officially launched its public beta.
The Xiaomi MiMo-V2.5 series includes MiMo-V2.5, V2.5-Pro, V2.5-TTS Series, and V2.5-ASR.
Stronger reasoning, more stable agents, longer context, stronger instruction following and understanding of ambiguous instructions, better full-modal perception and understanding —— this is a comprehensive leap from "usable" to "user-friendly".
Meanwhile, we have also optimized the Token Plan pricing plan —— making the world's top-notch models easily accessible.
## MiMo-V2.5-Pro: Stronger Agent, Longer Focus
MiMo-V2.5-Pro is our most powerful model to date. In dimensions such as **general agent capabilities, complex software engineering, and long-range tasks**, it can already compete head-on with the world's top Agent models (Claude Opus 4.6, GPT-5.4), achieving a comprehensive leap compared to the previous generation MiMo-V2-Pro.
During internal testing, the intelligence level demonstrated by MiMo-V2.5-Pro has made us rethink the way humans and models collaborate: when paired with a suitable operating framework, it can stably complete long-range tasks involving nearly a thousand rounds of tool calls in a single instance, and its instruction-following ability in the agent scenario has also significantly improved - it can accurately capture implicit requirements in the context and maintain logical consistency over an extremely long period. By now, MiMo-V2.5-Pro can already undertake truly serious professional work with a higher confidence level.
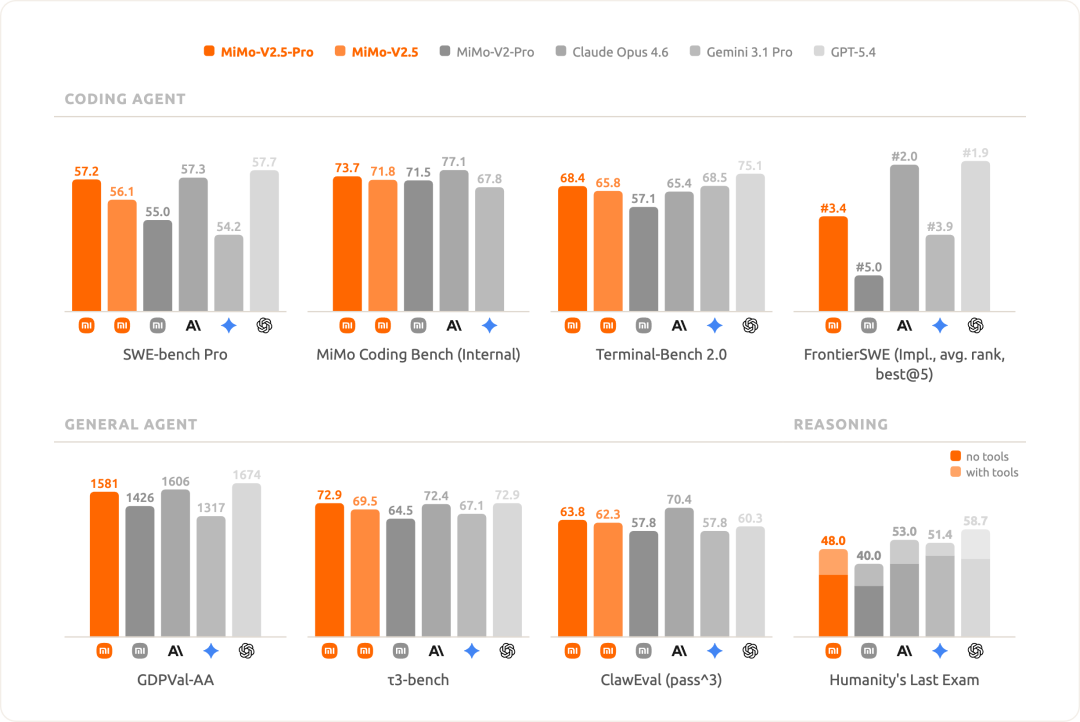
#### Designed for more complex tasks
MiMo-V2.5-Pro is designed for more challenging and complex task objectives. We assign tasks that would take human experts days or even weeks to complete to it, allowing it to independently complete long-term processes while still maintaining extremely high quality. The following are the results it has delivered:
##### **Implement a complete SysY compiler in Rust**
This task originated from the Compilation Principles course project at Peking University, requiring the model to implement a complete SysY compiler from scratch in Rust, including a lexical analyzer, a syntax analyzer, AST, Koopa IR code generation, RISC-V assembly backend, and performance optimization. For reference, **undergraduate students at Peking University usually take** **several weeks to complete this project, while MiMo-V2.5-Pro only took** **4.3 hours**, completed all tasks after 672 tool calls, and achieved **a perfect score of 233/233 on the hidden test set, demonstrating extremely high productivity value.**
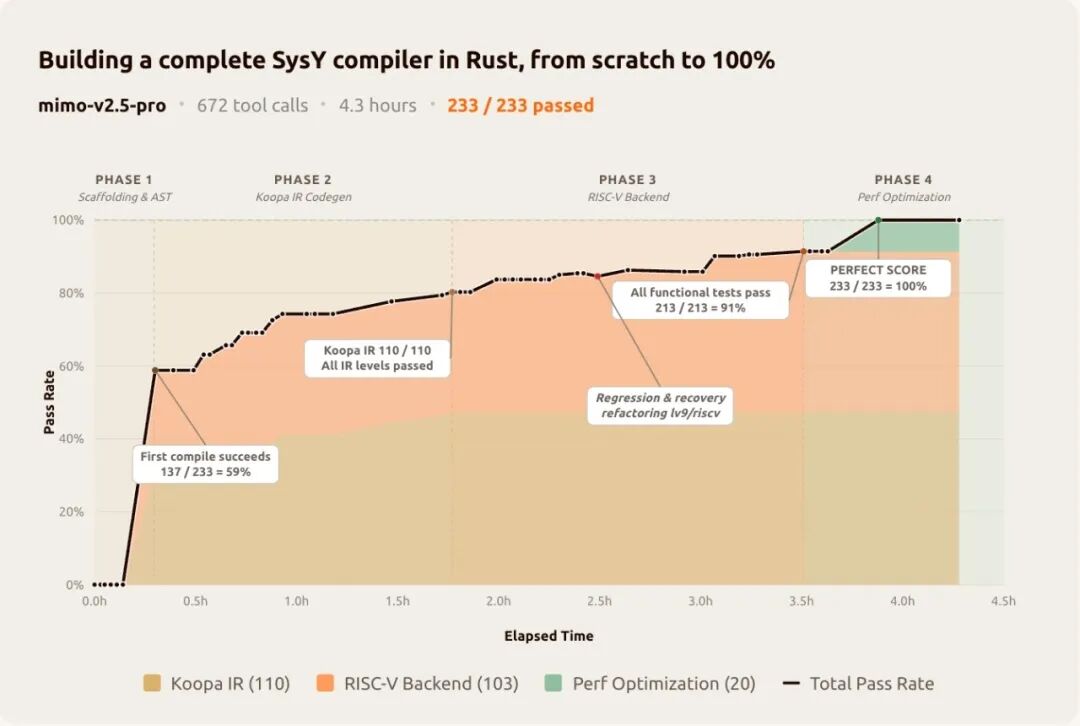
Instead of getting stuck in brute-force trial-and-error, it builds the entire compiler layer by layer: first constructing the complete pipeline framework, then tackling each layer one by one - Koopa IR achieved a perfect score (110/110), the RISC-V backend achieved a perfect score (103/103), and Performance optimization achieved a perfect score (20/20). The first compilation passed **137/233** , with a cold start pass rate of 59%, which means that the architecture was already correct before running any tests. In the 512th round, a refactoring caused lv9/riscv to regress by two test points; the model self-diagnosed, recovered, and continued to progress.
**The long-range task rewards precisely this structured and self-correcting work discipline.**
##### **Develop a video editor**
With just a few simple instructions - "Build a video editor web application" - MiMo-V2.5-Pro delivered a runnable web application: featuring multi-track timeline, clip trimming, cross-fading, audio mixing, and export processes. The final built codebase amounts to 8,192 lines, involves 1,868 tool invocations, and was completed in 11.5 hours of autonomous work.
## MiMo-V2.5: Overstepping Full-Modal Agent, Million Contexts
MiMo-V2.5 is a native full-modal large model designed for Agent scenarios, capable of seeing, hearing, and reading simultaneously, and translating understanding into action.
This time, MiMo-V2.5 brings a key upgrade:
**Agent capabilities comprehensively surpass MiMo-V2-Pro**
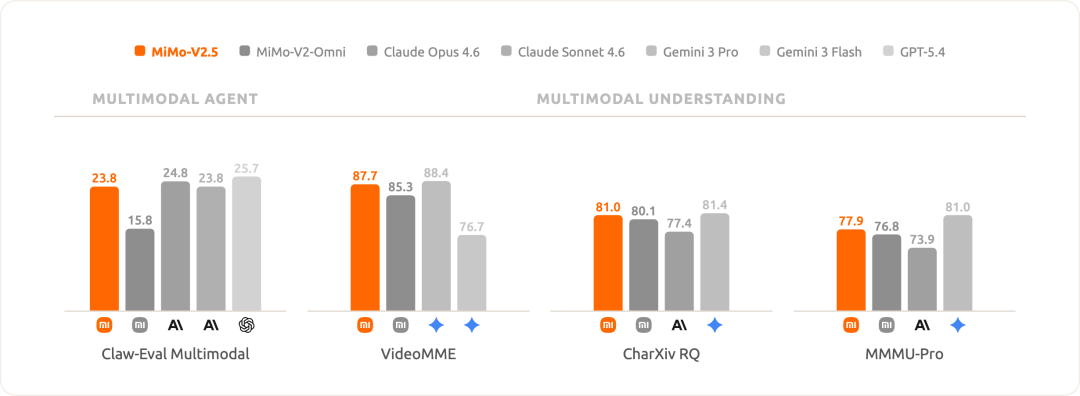
In authoritative Agent evaluations such as Claw-Eval, MiMo-V2.5 surpasses the level of MiMo-V2-Pro, is capable of handling daily simple tasks, and at the same time reduces API costs by approximately 50%.
**MultiModal Machine Learning perception comprehensively surpasses MiMo-V2-Omni**
Capabilities such as cross-modal reasoning, video understanding, and chart analysis have been enhanced, approaching and even surpassing industry-leading closed-source models in evaluations such as VideoMME, CharXiv, and MMMU-Pro.
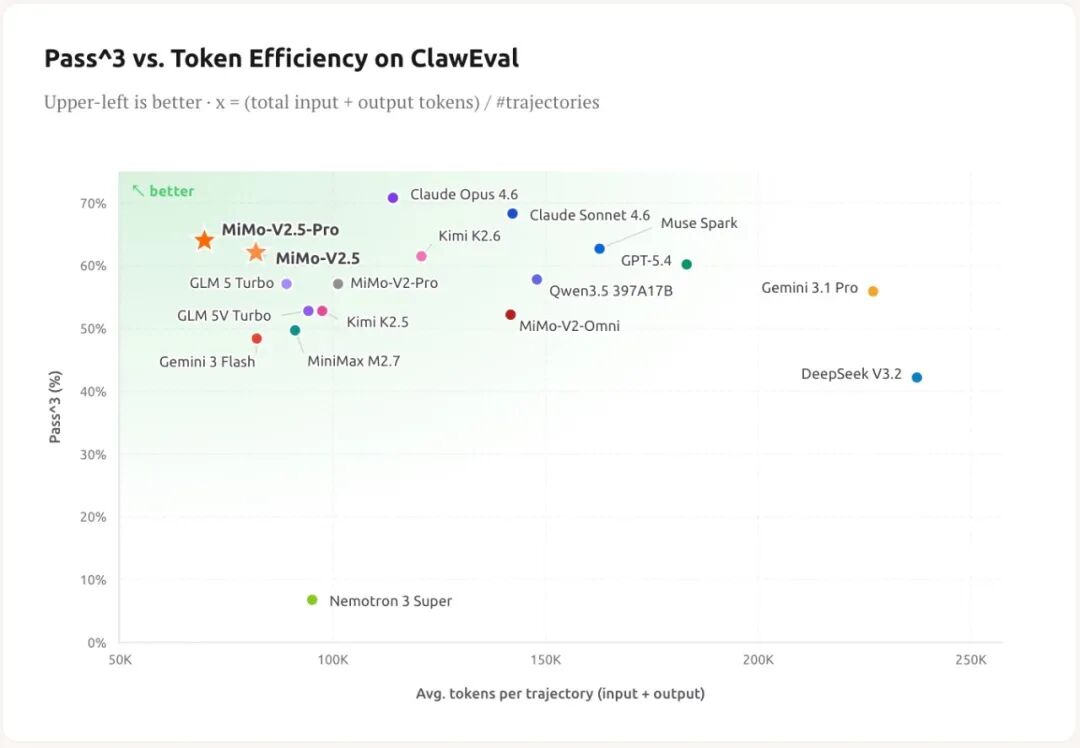
## MiMo-V2.5 Full Series: Higher Token Efficiency
The entire MiMo-V2.5 series is optimized for Token efficiency, doing more with fewer Tokens.
When achieving the same score on the Agent benchmark list ClawEval:
- MiMo-V2.5-Pro saves 42% Token compared to Kimi K2.6
- MiMo-V2.5 saves 50% of tokens compared to Muse Spark
## MiMo-V2.5 Full Series: How to Use Them in Combination?
- MiMo-V2.5-Pro is specifically designed for long and complex Agent tasks, while MiMo-V2.5 covers most general Agent scenarios
- MiMo-V2.5 supports native full-modal Agent capabilities, covering images, audio, and video
- MiMo-V2.5 has a higher average inference speed and can respond more quickly to latency-sensitive tasks

## Token Plan Upgraded and Refreshed
We have made several substantial optimizations suitable for you regarding the Token Plan:
**Credits rate updated, more favorable**
- MiMo-V2.5:1x(use 1 Token = 1 Credit)
- MiMo-V2.5-Pro: 2x(use 1 Token = 2 Credits)
**Cancel the billing method of 1 Token = 4 Credits. From now on, the Token Plan will no longer distinguish the Credit multiplier for 256k and 1M context windows.**
**Exclusive Nighttime Discount Rate**
From 00:00 to 08:00 Beijing Time every day, the consumption rate of Credits for all models**will be further discounted by 20% on top of the original rate**.
**Enjoy discounts with auto-renewal**
A new "Continuous Monthly Subscription" model has been added. Existing users who activate auto-renewal will enjoy a 30% discount on the next month's subscription, while new users will enjoy a 23% discount on the next month's subscription, both limited to one time.
A new "Annual" subscription cycle has been added. Subscribing once will enjoy an 12% discount for the whole year, and no longer be combined with the first purchase/auto-renewal discount.
## Online Benefit: Token Plan users' Credits will be fully reset
All users who have purchased the Token Plan (as of 22:00 on April 22, Beijing Time) **will have their Credits quota fully reset to zero**, and the calculation will start anew.
Xiaomi MiMo helps you start from scratch and unleash your creativity to the fullest!
> Note: This online welfare only resets the Credits limit, does not reset the package timing, and the validity period of purchased packages remains unchanged.

## is about to be open-sourced
MiMo-V2.5-Pro and MiMo-V2.5 models are about to be globally open-sourced. Stay tuned!
--- DOCUMENT: Xiaomi MiMo is now integrated with the top-tier Agent framework Hermes Agent and offers a two-week free trial ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/hermes-free.md
# Xiaomi MiMo is now integrated with the top-tier Agent framework Hermes Agent and offers a two-week free trial
The Xiaomi MiMo-V2 series now officially supports Hermes Agent!
As the flagship base for the Agent era, the Xiaomi MiMo-V2 series of large models has officially joined hands with the world's leading Agent open-source framework Hermes Agent to achieve official integrated access.
**Hermes Agent is:**
- One of the most globally watched open-source Agent frameworks currently
- It has the capabilities of self-evolution and cross-session memory, automatically accumulates experience from tasks, and becomes stronger with more use
- Supports cross-platform communication
MiMo-V2-Pro, with its 1M long context capability, native strong tool invocation, and in-depth Agent-specific optimization, is fully compatible with core features of Hermes Agent such as self-evolution skills, cross-session memory, and complex workflows.
MiMo-V2-Omni further expands the boundaries of perception, integrating the full-modal understanding capabilities of images, videos, audio, and text, enabling Hermes Agent to become a true full-modal agent that can see, understand, and act.
**We sincerely invite developers worldwide to try it out, with a two-week free trial**
- **Free trial period:** April 8 - April 22, 12:00 (Beijing Time, UTC+8), a total of two weeks.
- **Usage:** Update Hermes Agent to the latest version, and you can call Xiaomi MiMo-V2 Pro, Omni, and Flash models for free via Nous Portal.
From "task execution" to "self-evolution", MiMo, in collaboration with Hermes Agent, enables your AI Agent to become "smarter with use".

--- DOCUMENT: Xiaomi MiMo Token Plan Brand New Release ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/token-plan-release.md
# Xiaomi MiMo Token Plan Brand New Release
Since 2025, the capabilities of large models have been continuously redefined. However, for most developers and users, "affordability" remains a more fundamental issue than "usability". Under the pay-as-you-go model, every invocation is accompanied by uncertainty about costs.
We don't want it to be this way. We believe that ** good technology should not be a privilege reserved for only a few; it should, like water and electricity, become a readily accessible productivity tool for everyone at a predictable price.**
Therefore, we officially launch the Xiaomi MiMo Token Plan.
### MiMo Token Plan: Simplify Complexity
Our original intention in designing the Token Plan was to ensure that the billing method is transparent, simple, and straightforward enough for any user to understand and use with ease.
**1. Transparent design, simple and straightforward** - Unified Credit point system, converting credit consumption based on token usage, helping you easily plan your usage.
> - MiMo-V2-Omni 256k Context: 1x (1 Token Consumed = 1 Credit)
>
> - MiMo-V2-Pro 256k Context: 2x (1 Token Consumed = 2 Credits)
>
> - MiMo-V2-Pro 256k~1M Context: 4x (1 Token Consumed = 4 Credits)
>
> - MiMo-V2-TTS: 0x (Limited-time free, no Credit consumption)
**2. No 5-hour token usage limit** —— Supports concentrated token consumption, enabling high-intensity lobster farming or programming with a full experience and no interruptions.
**3. Users who purchase the package can enjoy the priority internal testing experience right for the new model**—advanced and user-friendly, one step ahead.
### Four-tier pricing, designed for you
Token Plan offers four tiers of packages, so no matter your frequency and depth of AI usage, you can find a suitable plan:
- **Lite (China: ¥39/month. Overseas: $6/month)** —— 60M Credits, can execute approximately **120 medium to complex tasks**. Suitable for explorers new to AI development, starting at the price of a cup of coffee.
- **Standard (China: ¥99/month. Overseas: $16/month)** —— 200M Credits, capable of performing approximately **400 medium to complex tasks**. A primary solution designed for work and developer users who rely on AI for daily efficiency improvement.
- **Pro (China: ¥329/month. Overseas: $50/month)** —— 700 million (700M) Credits, capable of performing approximately **1,400 medium to complex tasks**. Designed for professional users who deeply integrate AI into their workflows.
- **Max (China: ¥659/month. Overseas: $100/month)** —— 1.6 billion (1600M) Credits, capable of executing approximately **3200 medium to complex tasks**. Designed for developers with all-day, high-intensity usage, offering an almost unrestricted usage experience.
> All packages enjoy a **12% discount** on the first purchase, and this discount is limited to 1 time only.
>
> 
### Specifically adapted for mainstream AI tools
Specifically designed for mainstream AI tools and development platforms such as Claude Code, OpenClaw, OpenCode, Kilo Code, Cline, etc., to help you efficiently boost productivity.
### This is just the beginning
Auto-renewal, plan upgrades, and more flexible usage management are all under development. If you have any ideas or suggestions during use, we sincerely look forward to your feedback.
Token Plan is the new starting point for MiMo, and our goal has never changed:** to create the best models, set the most reasonable prices, and enable more people to truly use them.**
👉 Purchase Now: [Xiaomi MiMo Open Platform](https://platform.xiaomimimo.com/)

--- DOCUMENT: Xiaomi MiMo Agent Framework Call Free Trial Extension for One Week ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/free-trial-extension.md
# Xiaomi MiMo Agent Framework Call Free Trial Extension for One Week
Since the global release of the new models in the Xiaomi MiMo-V2 series on March 19, 2026, the MiMo-V2-Pro/Omni has been enthusiastically pursued and widely concerned by developers worldwide, especially the flagship model MiMo-V2-Pro in the global call volume ranking of OpenRouter**has continuously ranked No. 1 in the daily, weekly, and trending lists**.
In addition, our joint operation activities carried out together with **top Agent frameworks such as OpenClaw, OpenCode, KiloCode, Cline, and BlackBoxAI** are also highly popular among users.
Therefore, we have decided - **to extend the "XiaomiMiMo Launches First Week Free Trial in Collaboration with Global Top Agent Framework" event from the originally scheduled one-week free trial to two weeks,** and the free trial period will be extended to: **12:00 PM, April 2, 2026, Beijing Time (GMT+8).**
For the limited-time free access methods of each platform, please refer to:[Xiaomi MiMo Partners with Top Agent Framework : First Week Free](https://platform.xiaomimimo.com/#/docs/news/first-week-free)
AI without barriers, innovation without limits. We sincerely invite global developers to fully unleash the powerful productivity of the combination of Xiaomi MiMo large model and top-tier Agent framework.

--- DOCUMENT: Xiaomi MiMo Partners with Top Agent Framework : First Week Free ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/first-week-free.md
# Xiaomi MiMo Partners with Top Agent Framework : First Week Free

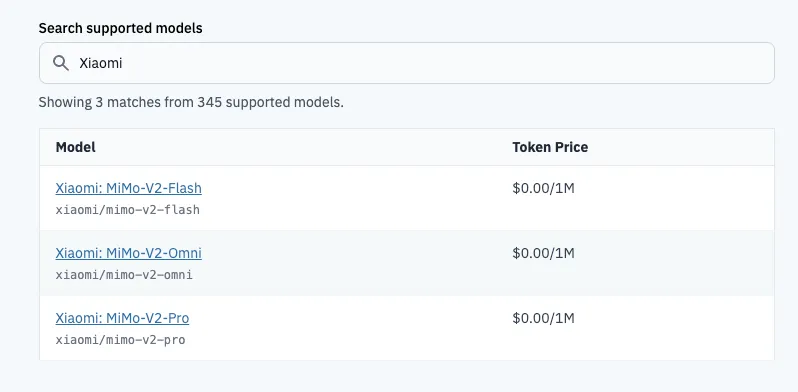
MiMo-V2-Pro, MiMo-V2-Omni, and MiMo-V2-TTS are now available. To meet global developers' anticipation for Xiaomi MiMo's new base models, Xiaomi MiMo has partnered with five agent frameworks — OpenClaw, OpenCode, KiloCode, Cline, and BLACKBOXAI — offering free API access worldwide for one week.
**Note: MiMo-V2-Pro and MiMo-V2-Omni can only be used for free in the above five agent frameworks, see below for detailed instructions. To call the Model API directly, see** [**Pricing and Rate Limits**](https://platform.xiaomimimo.com/#/docs/pricing) **for pricing standards.**
## 01 / OpenClaw
**Free for a Limited Time** — A Highly Anticipated General-Purpose Agent Framework. AI That Truly Gets Things Done.

#### Integration
Get an API Key from OpenRouter and configure it in your OpenClaw:
- In chat: `/model openrouter/xiaomi/mimo-v2-pro` (or v2-omni)
- In terminal: `openclaw models set openrouter/xiaomi/mimo-v2-pro` (or v2-omni)
- Or edit config: set `model.primary` to `openrouter/xiaomi/mimo-v2-pro` (or v2-omni)
See details on [OpenClaw provides free access to MiMo-V2-Pro/MiMo-V2-Omni replicas via Openrouter](https://platform.xiaomimimo.com/#/docs/integration/openclaw-with-openrouter) .
## 02 / OpenCode
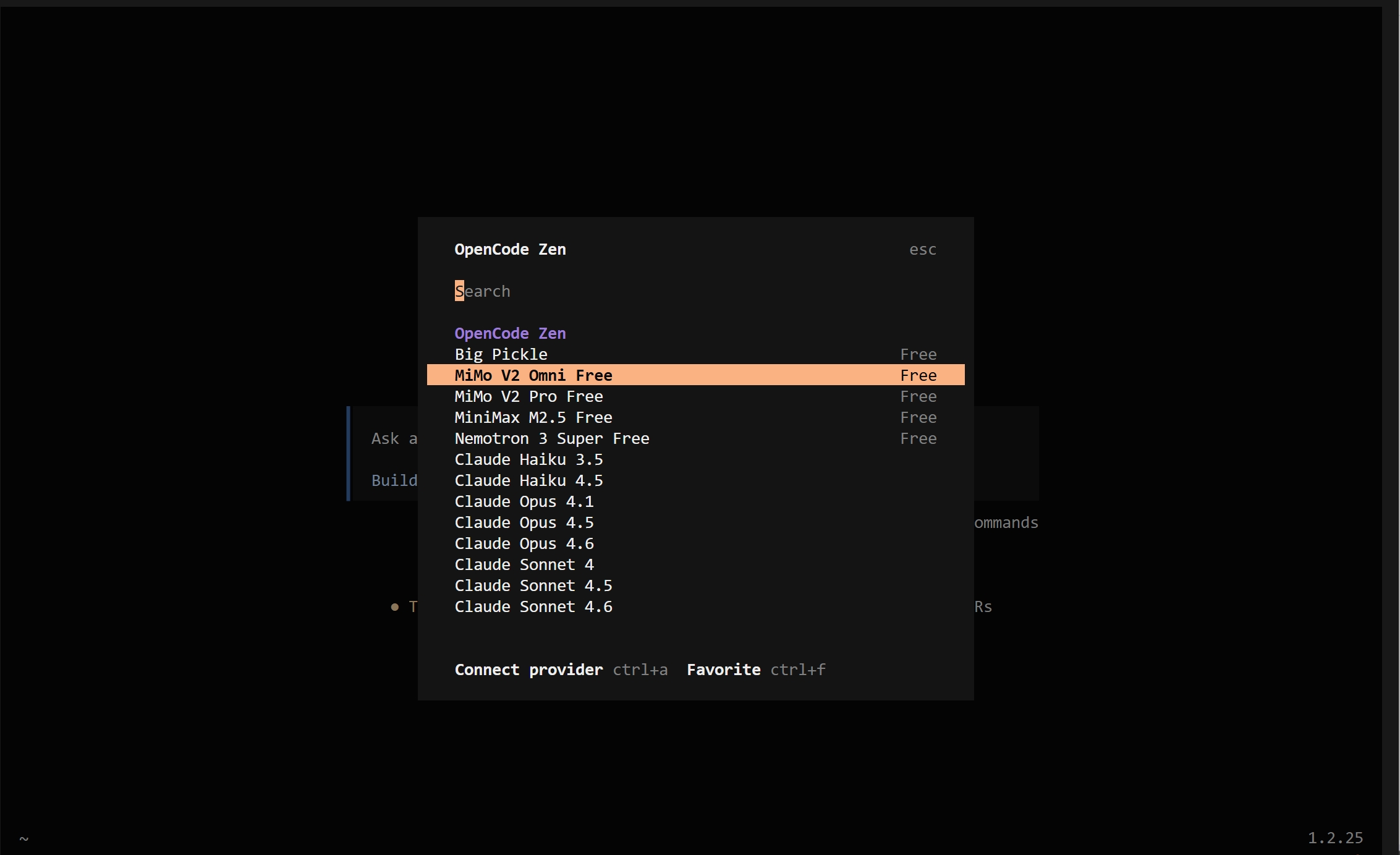
**Free for a Limited Time** — Open-Source AI Coding Agent. 120K+ GitHub Stars. 5M+ Developers Monthly.
#### Integration
From the terminal, desktop app, or IDE extension, select MiMo V2 Pro / MiMo V2 Omni (FREE tag) under OpenCode → Zen.
## 03 / KiloCode
**Free for a Limited Time —** A Full-Featured AI Engineering Platform for Developers. 1M+ Kilo Developers.
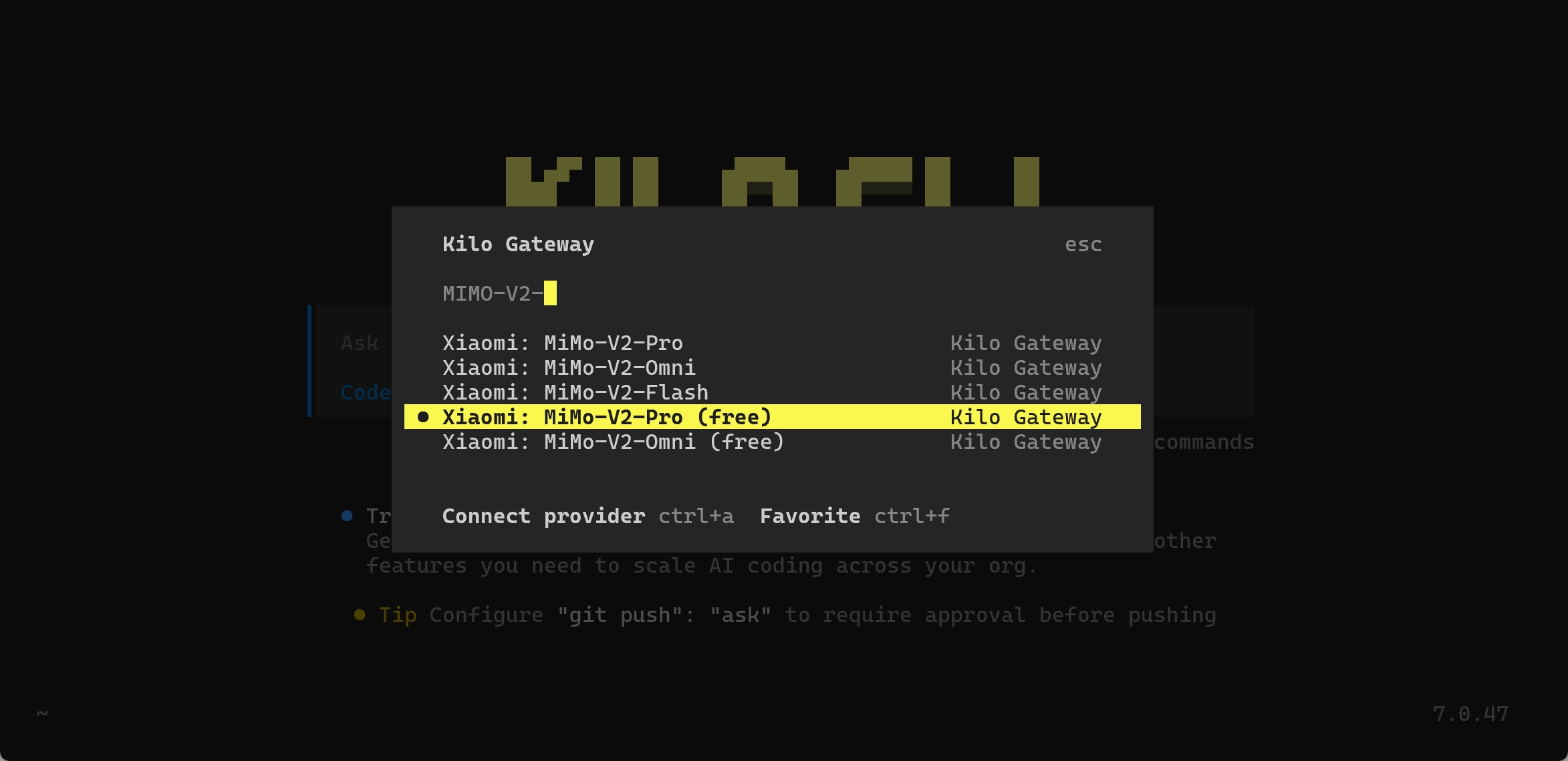
#### Integration
From the terminal or IDE extension, select MiMo V2 Pro / MiMo V2 Omni (FREE tag) under Kilo Gateway.
## 04 / Cline
**Free for a Limited Time —** AI Coding Assistant That Helps Developers Build and Refactor High-Quality Software at 2x Speed.

#### Integration
From the terminal or IDE extension, select Cline as the Provider and choose mimo-v2-pro (FREE tag).
## 05 / BLACKBOX.AI
One of the Fastest-Growing Coding Agents Globally — Committed to Redefining How You Write Code with AI.
Blackbox.AI is Currently in Final Testing and Coming Soon. Stay Tuned to Blackbox.AI's Official X Posts.

#### Integration
Select the model in the terminal, desktop app, or IDE extension to integrate.
## 06 / MiMo-V2-TTS
**Free for an Extended Period.** — Xiaomi's In-House Text-to-Speech Foundation Model. Empowering Agents with Warm, Expressive, and Soulful Voice.
#### Integration
Access via the official API platform.
For detailed integration, refer to: [MiMo-V2-TTS Usage Guide](https://platform.xiaomimimo.com/#/docs/usage-guide/speech-synthesis)

AI Without Barriers. Innovation Without Limits. Global Developers — Unleash the Power of Trillion-Parameter Models Paired with Top-Tier Agent Frameworks.

--- DOCUMENT: Xiaomi MiMo-V2-Pro: Flagship Foundation Model towards Agent Era ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/v2-pro-release.md
# Xiaomi MiMo-V2-Pro: Flagship Foundation Model towards Agent Era
Today, we are releasing Xiaomi MiMo-V2-Pro, Xiaomi’s flagship foundation model for the agent era.
Xiaomi MiMo-V2-Pro is built for demanding real-world Agent workflows. It has over **1T** total parameters, with **42B** active parameters, uses an innovative hybrid attention architecture, and supports an ultra-long context window of up to **1M** tokens. Based on the strong foundation model, we continue to scale compute across a broader range of agent scenarios, further expanding the action space of intelligence and achieving an important generalization leap from Coding to Claw.
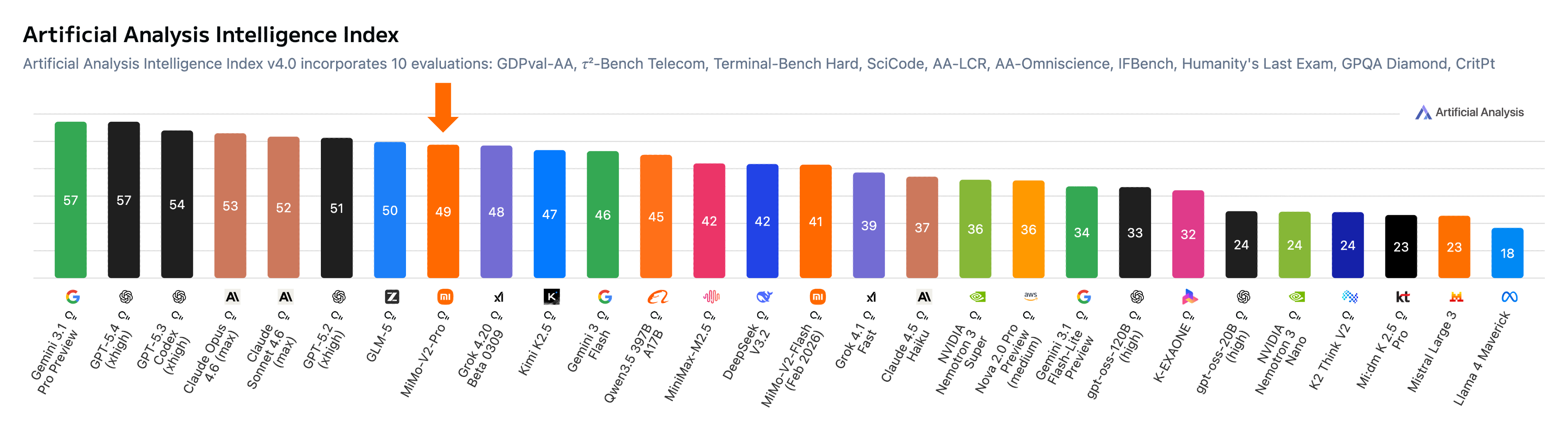
On the global authoritative model intelligence ranking by Artificial Analysis, MiMo-V2-Pro ranks eighth worldwide and second in China.
In agent frameworks such as OpenClaw and Claude Code, MiMo-V2-Pro shows excellent end-to-end task completion ability. It can handle complex workflow orchestration, long-horizon planning, and precise tool use without human intervention, while reliably delivering final results. In overall hands-on experience, it has surpassed Claude Sonnet 4.6 and is approaching Opus 4.6, while its API pricing is only one-fifth of theirs, lowering the barrier to using frontier intelligence.
## A major leap in foundation capabilities
By scaling both parameters and compute, MiMo-V2-Pro reaches to a larger and stronger model foundation.
- **Trillion-parameter scale, efficient architecture**: Total parameters exceed 1T, with 42B active parameters, about 3x larger than the previous MiMo-V2-Flash. It continues to use the innovative Hybrid Attention mechanism introduced in MiMo-V2-Flash, with the hybrid ratio further increased from 5:1 to 7:1. This keeps inference efficient even with the large increase in model size, while also supporting 1M-token context. A lightweight MTP (Multi-Token Prediction) layer enables fast generation.
- **From Chat to Agent**: By scaling during post-training across a broader set of Agent tasks, the model is no longer limited to “answering questions” or “generating polished demos.” It is built to complete tasks. We aim to integrate it deeply into productivity scenarios so it can serve as the “brain” behind working systems and continuously deliver results with real-world impact.
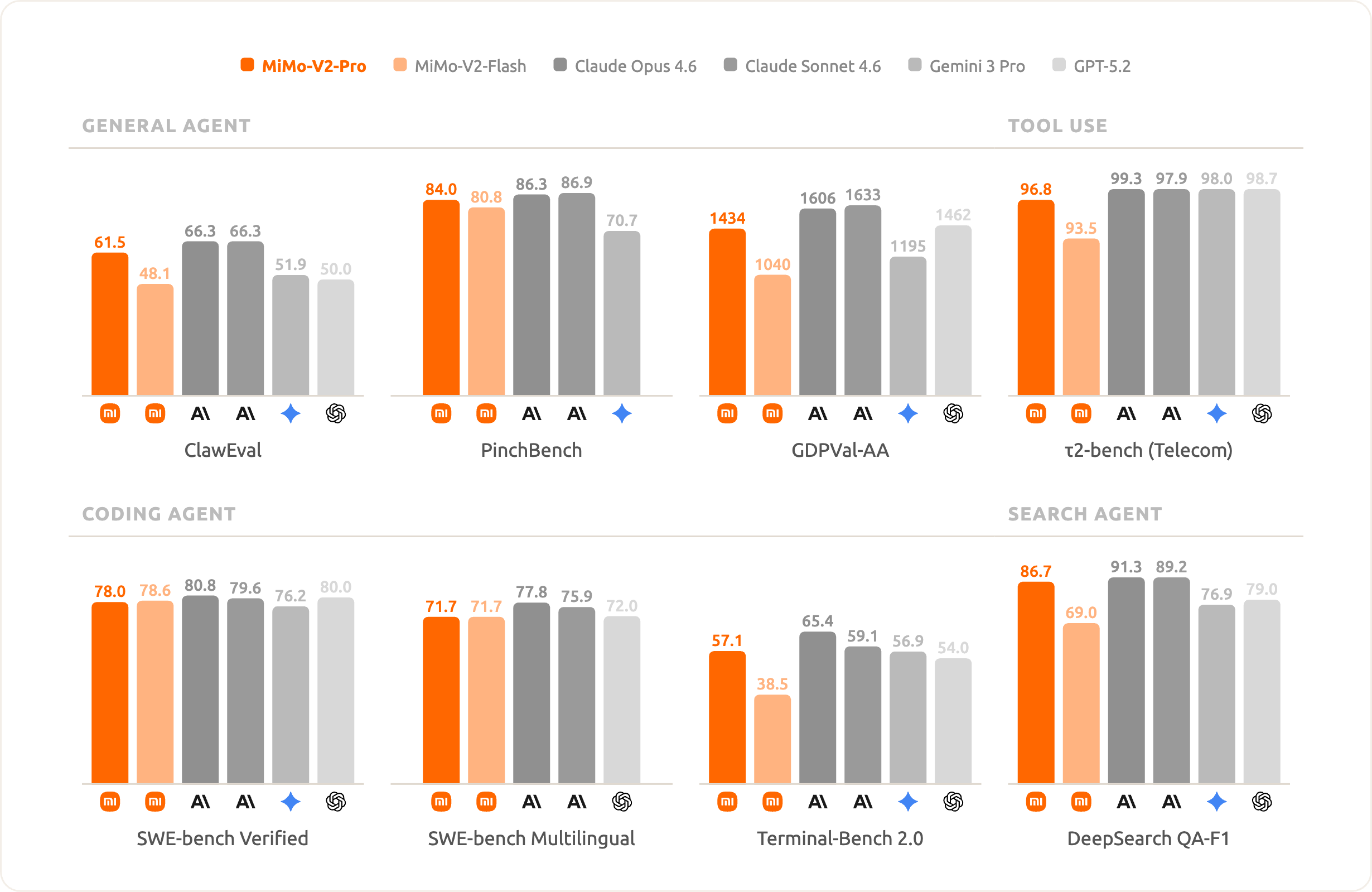
- **Real-world experience beyond benchmark rankings**: MiMo-V2-Pro performs strongly across benchmarks that measure key model capabilities. In Coding Agent, general Agent, and Tool Use tasks, it is in the same tier as Claude 4.5 Sonnet, GPT5.2, and Gemini 3.0 Pro, showing leading intelligence. We remain focused on training and optimization guided by actual user experience, always paying close attention to how the model performs in real applications.
## A flagship model built for Agents
MiMo-V2-Pro is deeply optimized specifically for Agent scenarios.
### The native brain for OpenClaw
OpenClaw is a general-purpose agent framework that has recently gained strong attention in the open-source community. As the core engine behind frameworks like this, the upper limit of the underlying model directly determines the system’s real-world performance. MiMo-V2-Pro is trained with SFT and RL on complex and diverse Agent scaffolds, giving it stronger tool-use and multi-step reasoning abilities.
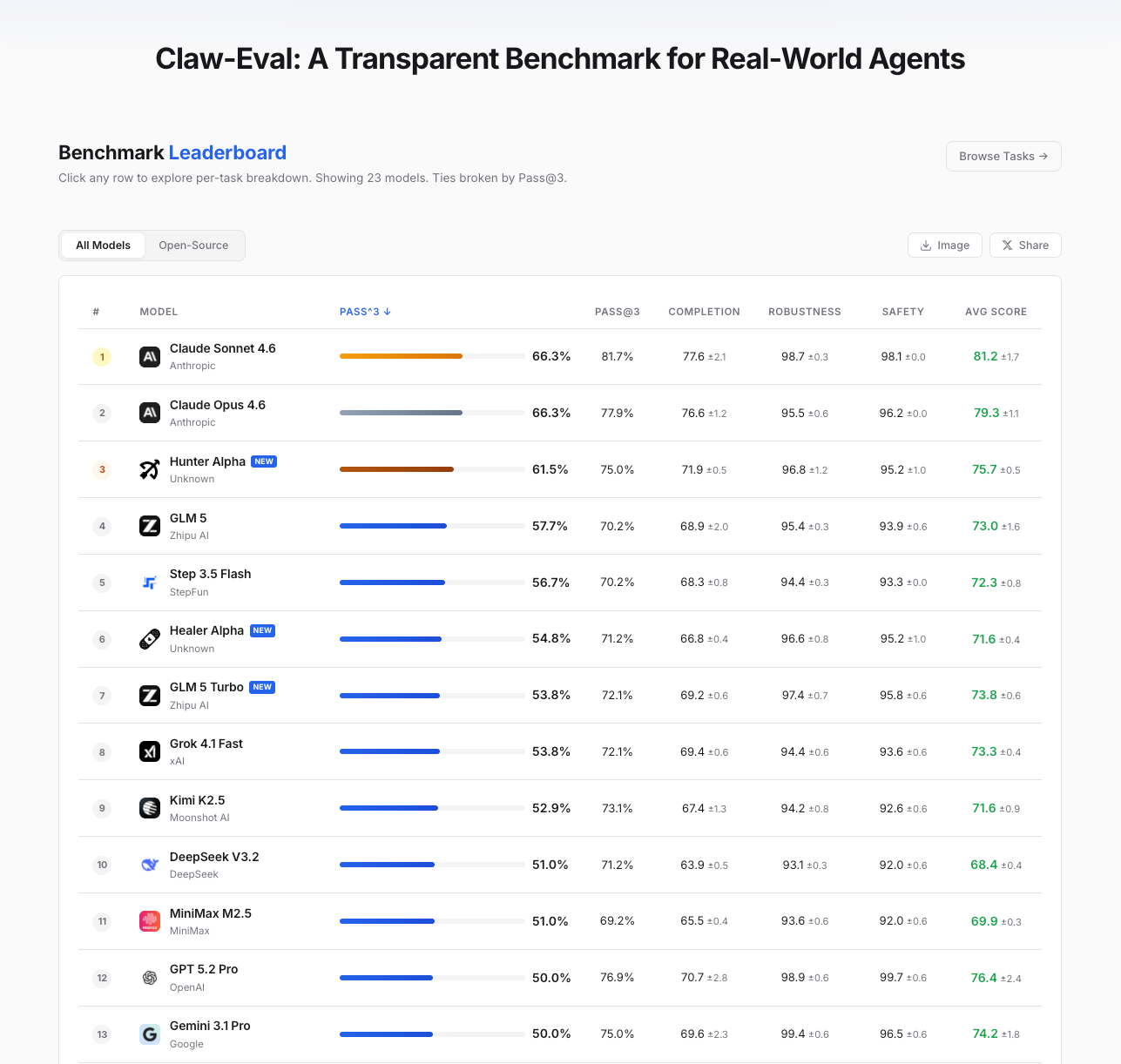
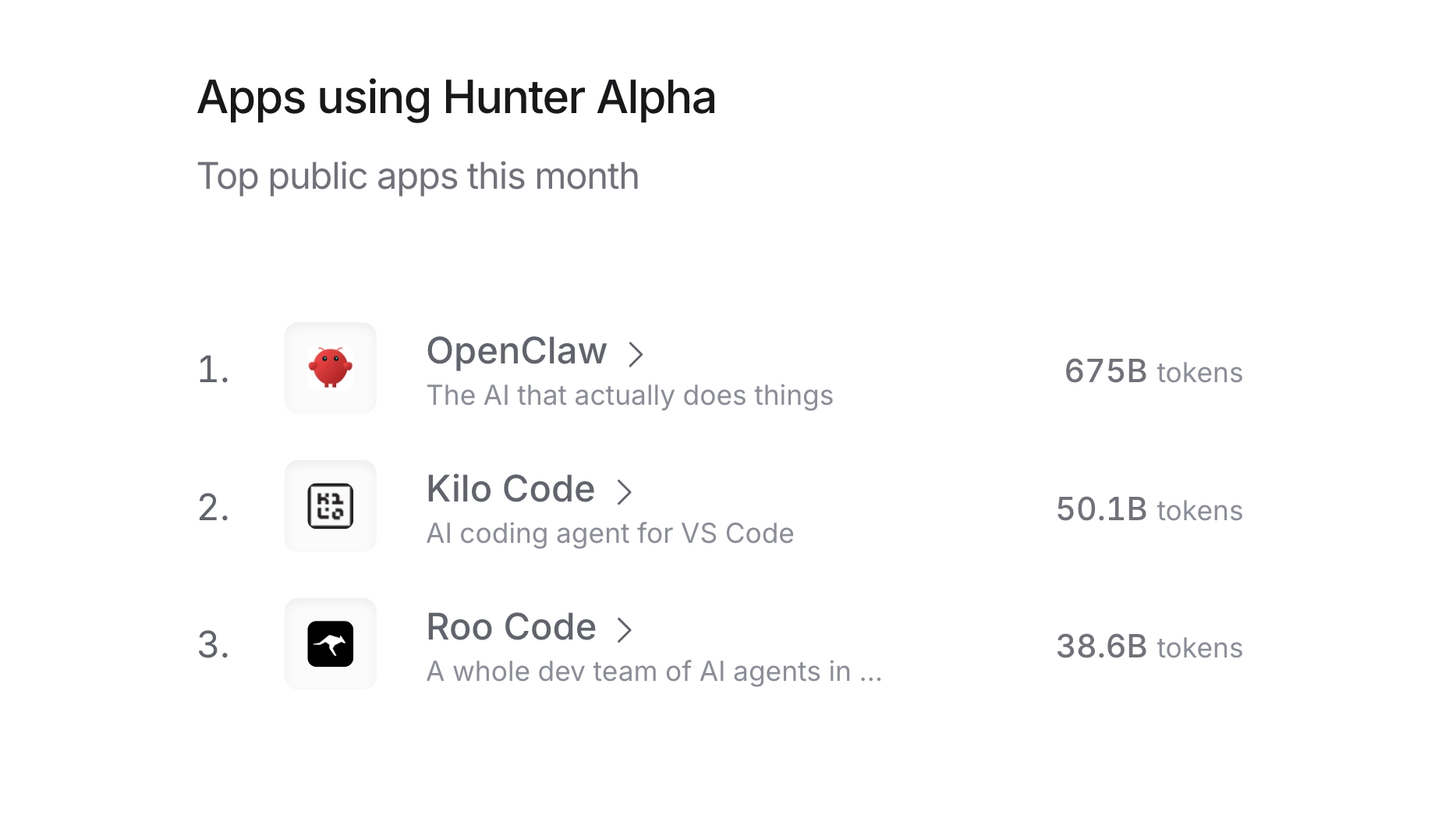
On OpenClaw’s standard benchmark leaderboards, PinchBench and ClawEval, MiMo-V2-Pro ranks among the best in the world. At the same time, with its 1M-token context window, MiMo-V2-Pro can comfortably support demanding real-world Claw application flows. Hunter Alpha shown below is an early anonymous version of MiMo-V2-Pro.
### Continuous Evolution of Coding Capabilities
Going beyond mere "Vibe Coding", MiMo-V2-Pro is capable of participating in more rigorous code engineering construction.
In in-depth evaluations by internal engineers at Xiaomi, MiMo-V2-Pro's user experience has approached that of Claude Opus 4.6, demonstrating advanced code intelligence: it boasts superior system design and task planning capabilities, more elegant coding styles, and more efficient, direct problem-solving pathways.
During the "Hunter Alpha" anonymous testing phase, the most frequently called apps were mostly programming-specific tools, which confirm MiMo-V2-Pro's high usability and reliability in real-world R&D scenarios.
## 1M Context Window, Open API
The MiMo-V2-Pro model is now officially available via API with pricing:
- Within 256K: Input at $1 / 1M tokens, Output at $3 / 1M tokens
- 256K ~ 1M: Input at $2 / 1M tokens, Output at $6 / 1M tokens
Visit [https://platform.xiaomimimo.com](https://platform.xiaomimimo.com/) to get started.
--- DOCUMENT: Xiaomi MiMo-V2-Omni: Omni-Modal Agentic Foundation Model that Sees, Understands and Acts ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/v2-omni-release.md
# Xiaomi MiMo-V2-Omni: Omni-Modal Agentic Foundation Model that Sees, Understands and Acts
Today, we are thrilled to announce Xiaomi’s omni‑modal foundation model for agent era: Xiaomi MiMo‑V2‑Omni.
Designed specifically for complex real‑world multimodal interaction and execution scenarios, MiMo‑V2‑Omni is built from the ground up as a unified all‑modal foundation that integrates text, vision, and speech. Its unified architecture deeply binds perception and action, overcoming the traditional limitation of models that prioritize understanding over execution.
Natively equipped with multimodal perception, tool invocation, function execution, and GUI operation capabilities, MiMo‑V2‑Omni seamlessly integrates with major agent frameworks. It enables a true leap from understanding to control, drastically lowering the barrier to deploying all‑modal agents.
## Perception Capabilities: Image, Video, and Audio on the Frontier
Accurate perception is the prerequisite for action. We benchmarked MiMo-V2-Omni against leading international models across all sensory modalities to ensure a rock-solid foundation for its capabilities as an AI agent.
**Visual Understanding**: MiMo-V2-Omni demonstrates robust multidisciplinary visual reasoning and complex chart analysis. It has surpassed Claude 4.6 Opus and is rapidly closing the gap with top-tier closed-source models like Gemini 3.
**Audio Understanding**: The model supports everything from environmental sound classification and multi-speaker separation to audio-visual joint reasoning and deep comprehension of continuous audio exceeding 10 hours. Its comprehensive performance exceeds Gemini 3 Pro, making it one of the most powerful audio understanding base models currently available.
**Video Understanding**: By supporting native audio-video joint input, we have achieved true multimodal video comprehension. Through innovative video pre-training, the model possesses powerful situational awareness and predictive reasoning capabilities.
When multiple modalities are processed simultaneously, the advantages of a unified architecture are magnified: cross-modal signals mutually reinforce one another rather than competing for resources.
## Agentic Capabilities: from Understanding to Execution
If perception is the foundation, then action is the ultimate goal.
A true AI agent model must be capable of observing complex environments across multiple modalities, formulating and executing plans, autonomously recovering from errors, and delivering end-to-end results.
### Omni-Modal Agent Tasks
MiMo-V2-Omni excels in benchmarks involving interaction with real-world digital environments, performing on par with Gemini 3 Pro. This success is underpinned by its industry-leading perceptual capabilities:The more accurate the perception, the more effective execution.
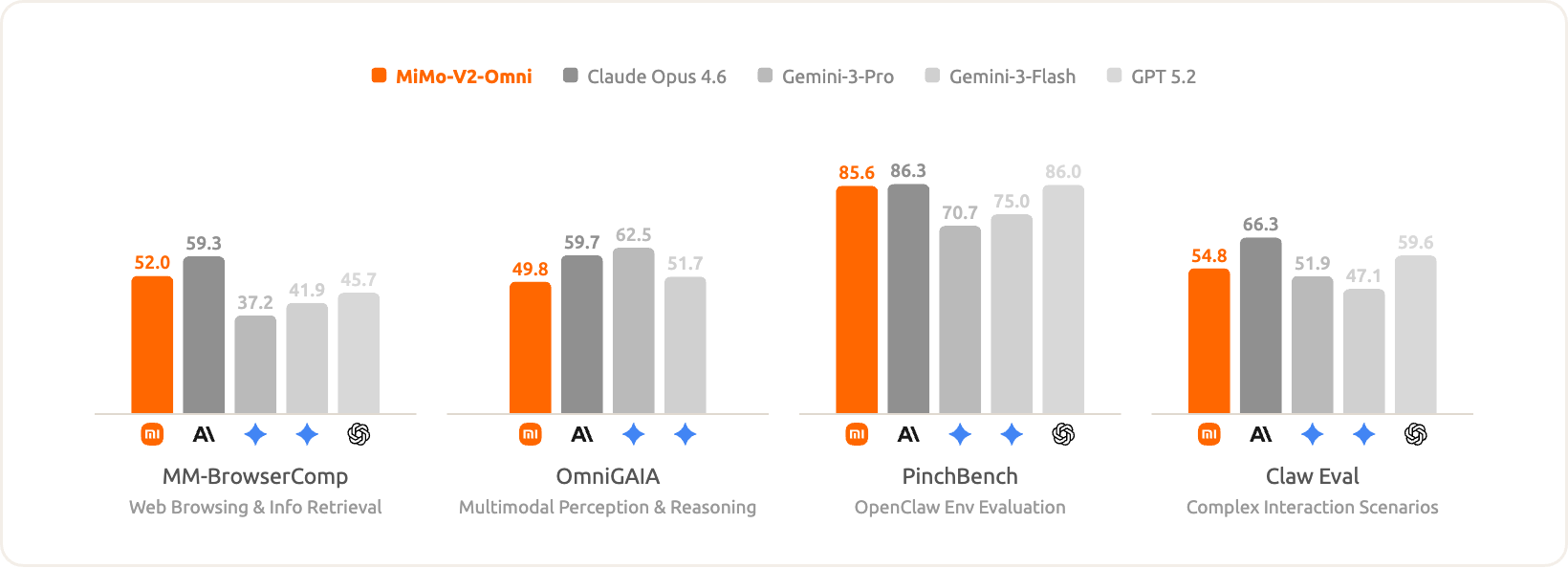
At the same time, MiMo-V2-Omni remains highly competitive in text-only agent tasks.
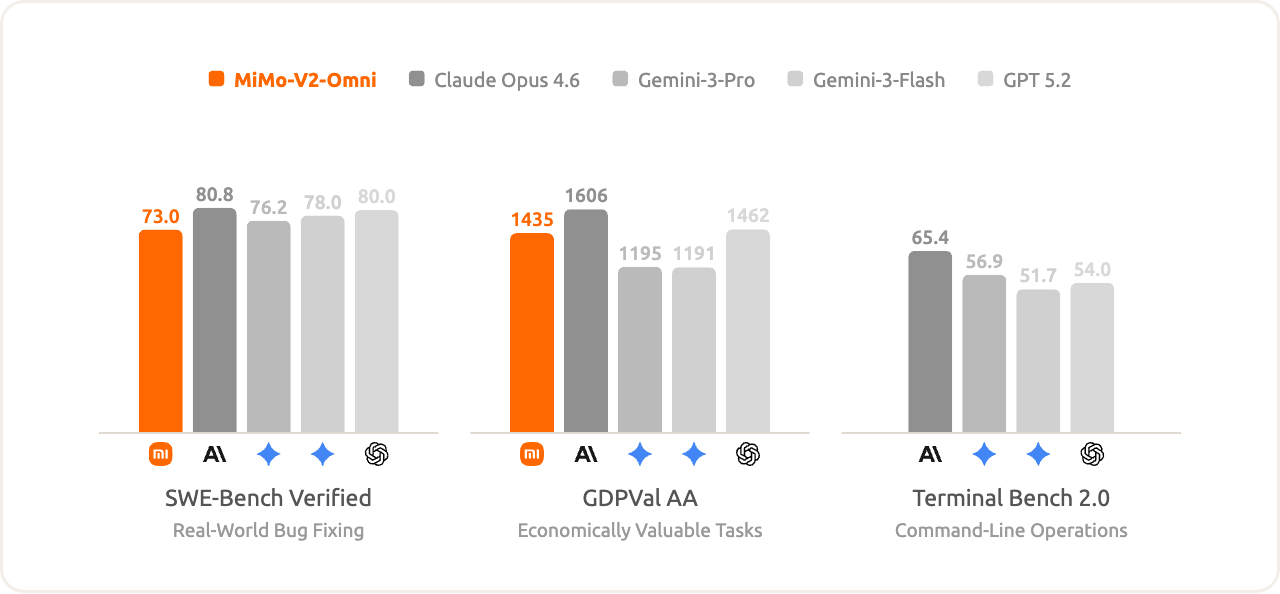
## Capabilities Demonstration
### 💻 Browser-Use Scenarios
Browser Use is the ultimate litmus test for a model’s agentic capabilities. It involves real-world interactions, dynamic web environments, heterogeneous interaction methods, and active anti-automation mechanisms. In these scenarios, the closed loop of perception, decision-making, and action operates continuously in an open environment until the mission is accomplished. When these same capabilities are ported to smart devices or robotics, they form the blueprint for General-Purpose Agents.
- **Shopping, Bargaining, and Ordering on Your Behalf**
We tested an end-to-end shopping task. Controlling the browser, the model first browsed over a dozen posts on Xiaohongshu to complete information gathering and obtain purchasing recommendations. It then performed cross-platform price comparisons across multiple stores on JD, followed by connecting with human customer service to bargain using natural language. After real-time interaction with the representative, it ultimately completed the process of adding items to the cart and placing the order. The model autonomously handled non-standard DOM structures, multi-tab context management, and workflow recovery after encountering platform anti-automation detections.
- **TikTok Video Creation and Publishing**
We tested an end-to-end video publishing task. The model autonomously designed four sets of visuals and synthesized all sound effects on-site with zero reliance on external assets. During rendering, it encountered a Chinese font error, which it self-corrected before continuing. It then controlled the browser to open the TikTok upload page, analyzed non-standard input controls to complete the copywriting, and proceeded to like and comment after clicking "Publish." Finally, it re-checked to confirm the video passed review and was publicly live.
### 🗒️ Smart Office Scenarios
Through natural dialogue, MiMo-V2-Omni can directly generate high-quality Word documents, structured Excel sheets, professionally formatted PDFs, and complete PPTs. These generated documents are no longer drafts requiring heavy revision, but high-quality "near-final versions" tailored to actual needs.
- **2026 Intelligent College Entrance Examination Application**
We tested the college entrance examination application planning task. The model can autonomously initiate web searches to obtain raw information, use skills to process files, and generate an Excel spreadsheet containing detailed application recommendations and tiered classifications.
## Open API
The MiMo-V2-Omni model is now officially available via API with pricing:
- Input: $0.4 / million tokens;
- Output: $2 / million tokens.
Visit [https://platform.xiaomimimo.com](https://platform.xiaomimimo.com/) to get started.
--- DOCUMENT: Xiaomi MiMo-V2-TTS: Versatile Voice Agent that Speaks and Sings ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/v2-tts-release.md
# Xiaomi MiMo-V2-TTS: Versatile Voice Agent that Speaks and Sings
**Xiaomi MiMo-V2-TTS** is a large-scale speech synthesis model independently developed by Xiaomi. Built on a proprietary audio tokenizer and a multi-codebook joint speech–text modeling architecture, it has been trained on hundreds of millions of hours of speech data with large-scale pretraining and multi-dimensional reinforcement learning, enabling highly controllable, fine-grained speech style generation. MiMo-V2-TTS supports precise control ranging from global style setting to nuanced local emotional expression. It can perform tone shifts and gradual emotional transitions within a single utterance, faithfully reproducing the natural prosody of human speech. When singing, it can also accurately render pitch and rhythm, delivering natural and expressive performance.
The MiMo-V2-TTS model is now available through the Xiaomi MiMo API open platform (https://platform.xiaomimimo.com), **with free access for a limited time**.
### Text Control
Flexible and customizable style control
MiMo-V2-TTS supports free-form natural language descriptions instead of being limited to predefined keywords. The model can understand and follow arbitrary descriptive instructions.
- Emotion control: happy, sad, angry, gentle, excited, calm…
- Dialect support: Northeastern Mandarin, Sichuan dialect, Henan dialect, Cantonese, Taiwanese accent…
- Role play: Monkey King, Lin Daiyu, Iron Man…
- Freely combined phrases — true natural language control: “cute and coquettish, soft ‘baby voice’,” “lazy, just woke up, slightly husky,” “deeply affectionate, slow speaking pace,” “passionate and powerful”
### Fine-grained control of vocal events
MiMo-V2-TTS can naturally insert and control various paralinguistic vocal events in speech, making the generated audio more realistic and expressive.
Supported vocal events: laughter, coughing, pauses, thinking/hesitation, sighing, etc.
## Deep Text Understanding
The model can intelligently recognize formatting cues in text and convert them into corresponding speech expressions—such as tone and punctuation—without requiring extra annotations.
Format awareness → speech rendering:
- ALL CAPS text (e.g., “THIS IS IMPORTANT”) → automatically adds emphasis;
- Repeated words or characters (e.g., “no no no no no”) → automatically mapped to matching rhythm and emotion.
During pretraining, the model learned from large-scale text–speech aligned data, enabling it to convert written formatting signals into natural-sounding speech.
## Beyond Speech: Dialects · Characters · Singing
MiMo-V2-TTS goes beyond standard speech synthesis with rich and versatile expressive capabilities. It supports natural pronunciation across multiple dialects, enables role-playing with stylized character performances, and delivers high-quality singing synthesis—allowing a single model to speak, act, and sing with ease.
## Open API
MiMo-V2-TTS is now officially available via API. **Free access is available for a limited time.**
Visit [https://platform.xiaomimimo.com](https://platform.xiaomimimo.com/) to get started.
--- DOCUMENT: MiMo-V2-Flash Release Note 2026/03/03 ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/news20260303.md
# MiMo-V2-Flash Release Note 2026/03/03
MiMo-V2-Flash now supports web search, enabling access to real-time public information (such as news, products, weather, etc.).
**Core Capabilities**
- **Flexible search modes**: Supports forced search and intent recognition. With intent recognition enabled, the model will autonomously decide whether to perform an online search without manual triggering.
- **Early search source return**: In the streaming response, the first packet will return all search sources.
- **Hybrid multi-tool invocation**: Can work with custom functions and tools; the model will automatically determine invocation priority and necessity.
- **Flexible response modes**: Supports both streaming and non-streaming responses, and both methods will return search and summary content.
**Use Cases**
- **Real-Time News Aggregation**
- Scenario: A user asks, "What are today's top stories about domestic large language models?"
- Capability: The model automatically generates search keywords like "Chinese LLM latest news March 1 2026," searches the web, and returns a summarized response with source links.
- **Product Information & Price Comparison**
- Scenario: A user asks, "What are the price and user reviews for the latest model of [Brand] phone?"
- Capability: The model searches multiple e-commerce platforms for pricing and reviews, then organizes the information into a concise summary to aid decision-making.
- **Real-Time Weather & Travel Information**
- Scenario: A user asks, "Is the weather in Shanghai tomorrow good for going out?"
- Capability: The model fetches the Shanghai weather forecast and provides practical suggestions based on common sense, such as "Rain expected tomorrow in Shanghai, temperatures 10–15°C. Bring an umbrella and dress warmly."
**Instructions and Recommendations**
1. **Enable Web Search Plugin**: Before using this feature, you need to activate the [Web Search Plugin](https://platform.xiaomimimo.com/#/console/plugin). For detailed parameters and invocation instructions, please refer to the [OpenAI API](https://platform.xiaomimimo.com/#/docs/api/text-generation/openai-api).
1. **Fees**: The web search feature incurs additional token consumption for generating search queries and processing results. A separate fee will also be charged per search call. For details, see [Web Search](https://platform.xiaomimimo.com/#/docs/usage-guide/tool-calling/web-search).
--- DOCUMENT: MiMo-V2-Flash Release Note 2026/02/04 ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/news20260212.md
# MiMo-V2-Flash Release Note 2026/02/04
1. **Upgraded Coding Capabilities in Thinking Mode:**
Specifically optimized for programming scenarios, the Thinking Mode now achieves a score of **78.6** on SWE-Bench Verified. Both the resolution rate and the quality of code generation have been significantly improved.
1. **Substantial Boost in Tool Calling Accuracy:**
Stability issues regarding tool usage have been resolved. Tool calling accuracy in Thinking Mode has surged from 64% to **97.0%**, greatly enhancing execution reliability in Agent scenarios.
1. **Enhanced Instruction Following & Reduced Hallucinations:**
- **Instruction Following:** Improved adherence to specific instructions, achieving an **AA-IFBench score of 72**.
- **Factuality:** Enhanced rigor in factual responses, with the **Non-Hallucination Rate updated to 52%**.
1. **Optimized Handling of Complex Tasks:**
Performance on Arena-Hard (Hard Prompts) in Thinking Mode has been strengthened, with the score rising to **60.6**. The model now demonstrates superior performance when handling high-difficulty logic problems.
1. **More Efficient Chain-of-Thought (CoT):**
By optimizing CoT generation strategies, the consumption of redundant tokens has been significantly reduced. In benchmarks such as AIME25 and HMMT, the average generation length has decreased by **13% to 30%**. This effectively lowers latency and token costs while maintaining model performance.
| | **MiMo-V2-Flash-0204** | **MiMo-V2-Flash-0112** | **MiMo-V2-Flash** |
| --- | --- | --- | --- |
| **SWE-Bench Verified**
--- DOCUMENT: Xiaomi MiMo-V2.5 Series Large Model Launches Public Beta ---
URL: https://platform.xiaomimimo.com/static/docs/news/v2.5-news.md
# Xiaomi MiMo-V2.5 Series Large Model Launches Public Beta

Today, the Xiaomi MiMo-V2.5 series of models officially launched its public beta.
The Xiaomi MiMo-V2.5 series includes MiMo-V2.5, V2.5-Pro, V2.5-TTS Series, and V2.5-ASR.
Stronger reasoning, more stable agents, longer context, stronger instruction following and understanding of ambiguous instructions, better full-modal perception and understanding —— this is a comprehensive leap from "usable" to "user-friendly".
Meanwhile, we have also optimized the Token Plan pricing plan —— making the world's top-notch models easily accessible.
## MiMo-V2.5-Pro: Stronger Agent, Longer Focus
MiMo-V2.5-Pro is our most powerful model to date. In dimensions such as **general agent capabilities, complex software engineering, and long-range tasks**, it can already compete head-on with the world's top Agent models (Claude Opus 4.6, GPT-5.4), achieving a comprehensive leap compared to the previous generation MiMo-V2-Pro.
During internal testing, the intelligence level demonstrated by MiMo-V2.5-Pro has made us rethink the way humans and models collaborate: when paired with a suitable operating framework, it can stably complete long-range tasks involving nearly a thousand rounds of tool calls in a single instance, and its instruction-following ability in the agent scenario has also significantly improved - it can accurately capture implicit requirements in the context and maintain logical consistency over an extremely long period. By now, MiMo-V2.5-Pro can already undertake truly serious professional work with a higher confidence level.

#### Designed for more complex tasks
MiMo-V2.5-Pro is designed for more challenging and complex task objectives. We assign tasks that would take human experts days or even weeks to complete to it, allowing it to independently complete long-term processes while still maintaining extremely high quality. The following are the results it has delivered:
##### **Implement a complete SysY compiler in Rust**
This task originated from the Compilation Principles course project at Peking University, requiring the model to implement a complete SysY compiler from scratch in Rust, including a lexical analyzer, a syntax analyzer, AST, Koopa IR code generation, RISC-V assembly backend, and performance optimization. For reference, **undergraduate students at Peking University usually take** **several weeks to complete this project, while MiMo-V2.5-Pro only took** **4.3 hours**, completed all tasks after 672 tool calls, and achieved **a perfect score of 233/233 on the hidden test set, demonstrating extremely high productivity value.**

Instead of getting stuck in brute-force trial-and-error, it builds the entire compiler layer by layer: first constructing the complete pipeline framework, then tackling each layer one by one - Koopa IR achieved a perfect score (110/110), the RISC-V backend achieved a perfect score (103/103), and Performance optimization achieved a perfect score (20/20). The first compilation passed **137/233** , with a cold start pass rate of 59%, which means that the architecture was already correct before running any tests. In the 512th round, a refactoring caused lv9/riscv to regress by two test points; the model self-diagnosed, recovered, and continued to progress.
**The long-range task rewards precisely this structured and self-correcting work discipline.**
##### **Develop a video editor**
With just a few simple instructions - "Build a video editor web application" - MiMo-V2.5-Pro delivered a runnable web application: featuring multi-track timeline, clip trimming, cross-fading, audio mixing, and export processes. The final built codebase amounts to 8,192 lines, involves 1,868 tool invocations, and was completed in 11.5 hours of autonomous work.
## MiMo-V2.5: Overstepping Full-Modal Agent, Million Contexts
MiMo-V2.5 is a native full-modal large model designed for Agent scenarios, capable of seeing, hearing, and reading simultaneously, and translating understanding into action.
This time, MiMo-V2.5 brings a key upgrade:
**Agent capabilities comprehensively surpass MiMo-V2-Pro**
In authoritative Agent evaluations such as Claw-Eval, MiMo-V2.5 surpasses the level of MiMo-V2-Pro, is capable of handling daily simple tasks, and at the same time reduces API costs by approximately 50%.
**MultiModal Machine Learning perception comprehensively surpasses MiMo-V2-Omni**
Capabilities such as cross-modal reasoning, video understanding, and chart analysis have been enhanced, approaching and even surpassing industry-leading closed-source models in evaluations such as VideoMME, CharXiv, and MMMU-Pro.

## MiMo-V2.5 Full Series: Higher Token Efficiency
The entire MiMo-V2.5 series is optimized for Token efficiency, doing more with fewer Tokens.
When achieving the same score on the Agent benchmark list ClawEval:
- MiMo-V2.5-Pro saves 42% Token compared to Kimi K2.6
- MiMo-V2.5 saves 50% of tokens compared to Muse Spark

## MiMo-V2.5 Full Series: How to Use Them in Combination?
- MiMo-V2.5-Pro is specifically designed for long and complex Agent tasks, while MiMo-V2.5 covers most general Agent scenarios
- MiMo-V2.5 supports native full-modal Agent capabilities, covering images, audio, and video
- MiMo-V2.5 has a higher average inference speed and can respond more quickly to latency-sensitive tasks

## Token Plan Upgraded and Refreshed
We have made several substantial optimizations suitable for you regarding the Token Plan:
**Credits rate updated, more favorable**
- MiMo-V2.5:1x(use 1 Token = 1 Credit)
- MiMo-V2.5-Pro: 2x(use 1 Token = 2 Credits)
**Cancel the billing method of 1 Token = 4 Credits. From now on, the Token Plan will no longer distinguish the Credit multiplier for 256k and 1M context windows.**
**Exclusive Nighttime Discount Rate**
From 00:00 to 08:00 Beijing Time every day, the consumption rate of Credits for all models**will be further discounted by 20% on top of the original rate**.
**Enjoy discounts with auto-renewal**
A new "Continuous Monthly Subscription" model has been added. Existing users who activate auto-renewal will enjoy a 30% discount on the next month's subscription, while new users will enjoy a 23% discount on the next month's subscription, both limited to one time.
A new "Annual" subscription cycle has been added. Subscribing once will enjoy an 12% discount for the whole year, and no longer be combined with the first purchase/auto-renewal discount.
## Online Benefit: Token Plan users' Credits will be fully reset
All users who have purchased the Token Plan (as of 22:00 on April 22, Beijing Time) **will have their Credits quota fully reset to zero**, and the calculation will start anew.
Xiaomi MiMo helps you start from scratch and unleash your creativity to the fullest!
> Note: This online welfare only resets the Credits limit, does not reset the package timing, and the validity period of purchased packages remains unchanged.

## is about to be open-sourced
MiMo-V2.5-Pro and MiMo-V2.5 models are about to be globally open-sourced. Stay tuned!
--- DOCUMENT: Xiaomi MiMo is now integrated with the top-tier Agent framework Hermes Agent and offers a two-week free trial ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/hermes-free.md
# Xiaomi MiMo is now integrated with the top-tier Agent framework Hermes Agent and offers a two-week free trial
The Xiaomi MiMo-V2 series now officially supports Hermes Agent!
As the flagship base for the Agent era, the Xiaomi MiMo-V2 series of large models has officially joined hands with the world's leading Agent open-source framework Hermes Agent to achieve official integrated access.
**Hermes Agent is:**
- One of the most globally watched open-source Agent frameworks currently
- It has the capabilities of self-evolution and cross-session memory, automatically accumulates experience from tasks, and becomes stronger with more use
- Supports cross-platform communication
MiMo-V2-Pro, with its 1M long context capability, native strong tool invocation, and in-depth Agent-specific optimization, is fully compatible with core features of Hermes Agent such as self-evolution skills, cross-session memory, and complex workflows.
MiMo-V2-Omni further expands the boundaries of perception, integrating the full-modal understanding capabilities of images, videos, audio, and text, enabling Hermes Agent to become a true full-modal agent that can see, understand, and act.
**We sincerely invite developers worldwide to try it out, with a two-week free trial**
- **Free trial period:** April 8 - April 22, 12:00 (Beijing Time, UTC+8), a total of two weeks.
- **Usage:** Update Hermes Agent to the latest version, and you can call Xiaomi MiMo-V2 Pro, Omni, and Flash models for free via Nous Portal.

From "task execution" to "self-evolution", MiMo, in collaboration with Hermes Agent, enables your AI Agent to become "smarter with use".

--- DOCUMENT: Xiaomi MiMo Token Plan Brand New Release ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/token-plan-release.md
# Xiaomi MiMo Token Plan Brand New Release
Since 2025, the capabilities of large models have been continuously redefined. However, for most developers and users, "affordability" remains a more fundamental issue than "usability". Under the pay-as-you-go model, every invocation is accompanied by uncertainty about costs.
We don't want it to be this way. We believe that ** good technology should not be a privilege reserved for only a few; it should, like water and electricity, become a readily accessible productivity tool for everyone at a predictable price.**
Therefore, we officially launch the Xiaomi MiMo Token Plan.
### MiMo Token Plan: Simplify Complexity
Our original intention in designing the Token Plan was to ensure that the billing method is transparent, simple, and straightforward enough for any user to understand and use with ease.
**1. Transparent design, simple and straightforward** - Unified Credit point system, converting credit consumption based on token usage, helping you easily plan your usage.
> - MiMo-V2-Omni 256k Context: 1x (1 Token Consumed = 1 Credit)
>
> - MiMo-V2-Pro 256k Context: 2x (1 Token Consumed = 2 Credits)
>
> - MiMo-V2-Pro 256k~1M Context: 4x (1 Token Consumed = 4 Credits)
>
> - MiMo-V2-TTS: 0x (Limited-time free, no Credit consumption)
**2. No 5-hour token usage limit** —— Supports concentrated token consumption, enabling high-intensity lobster farming or programming with a full experience and no interruptions.
**3. Users who purchase the package can enjoy the priority internal testing experience right for the new model**—advanced and user-friendly, one step ahead.

### Four-tier pricing, designed for you
Token Plan offers four tiers of packages, so no matter your frequency and depth of AI usage, you can find a suitable plan:
- **Lite (China: ¥39/month. Overseas: $6/month)** —— 60M Credits, can execute approximately **120 medium to complex tasks**. Suitable for explorers new to AI development, starting at the price of a cup of coffee.
- **Standard (China: ¥99/month. Overseas: $16/month)** —— 200M Credits, capable of performing approximately **400 medium to complex tasks**. A primary solution designed for work and developer users who rely on AI for daily efficiency improvement.
- **Pro (China: ¥329/month. Overseas: $50/month)** —— 700 million (700M) Credits, capable of performing approximately **1,400 medium to complex tasks**. Designed for professional users who deeply integrate AI into their workflows.
- **Max (China: ¥659/month. Overseas: $100/month)** —— 1.6 billion (1600M) Credits, capable of executing approximately **3200 medium to complex tasks**. Designed for developers with all-day, high-intensity usage, offering an almost unrestricted usage experience.
> All packages enjoy a **12% discount** on the first purchase, and this discount is limited to 1 time only.
>
> 
### Specifically adapted for mainstream AI tools
Specifically designed for mainstream AI tools and development platforms such as Claude Code, OpenClaw, OpenCode, Kilo Code, Cline, etc., to help you efficiently boost productivity.
### This is just the beginning
Auto-renewal, plan upgrades, and more flexible usage management are all under development. If you have any ideas or suggestions during use, we sincerely look forward to your feedback.
Token Plan is the new starting point for MiMo, and our goal has never changed:** to create the best models, set the most reasonable prices, and enable more people to truly use them.**
👉 Purchase Now: [Xiaomi MiMo Open Platform](https://platform.xiaomimimo.com/)

--- DOCUMENT: Xiaomi MiMo Agent Framework Call Free Trial Extension for One Week ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/free-trial-extension.md
# Xiaomi MiMo Agent Framework Call Free Trial Extension for One Week
Since the global release of the new models in the Xiaomi MiMo-V2 series on March 19, 2026, the MiMo-V2-Pro/Omni has been enthusiastically pursued and widely concerned by developers worldwide, especially the flagship model MiMo-V2-Pro in the global call volume ranking of OpenRouter**has continuously ranked No. 1 in the daily, weekly, and trending lists**.
In addition, our joint operation activities carried out together with **top Agent frameworks such as OpenClaw, OpenCode, KiloCode, Cline, and BlackBoxAI** are also highly popular among users.
Therefore, we have decided - **to extend the "XiaomiMiMo Launches First Week Free Trial in Collaboration with Global Top Agent Framework" event from the originally scheduled one-week free trial to two weeks,** and the free trial period will be extended to: **12:00 PM, April 2, 2026, Beijing Time (GMT+8).**
For the limited-time free access methods of each platform, please refer to:[Xiaomi MiMo Partners with Top Agent Framework : First Week Free](https://platform.xiaomimimo.com/#/docs/news/first-week-free)
AI without barriers, innovation without limits. We sincerely invite global developers to fully unleash the powerful productivity of the combination of Xiaomi MiMo large model and top-tier Agent framework.

--- DOCUMENT: Xiaomi MiMo Partners with Top Agent Framework : First Week Free ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/first-week-free.md
# Xiaomi MiMo Partners with Top Agent Framework : First Week Free

MiMo-V2-Pro, MiMo-V2-Omni, and MiMo-V2-TTS are now available. To meet global developers' anticipation for Xiaomi MiMo's new base models, Xiaomi MiMo has partnered with five agent frameworks — OpenClaw, OpenCode, KiloCode, Cline, and BLACKBOXAI — offering free API access worldwide for one week.
**Note: MiMo-V2-Pro and MiMo-V2-Omni can only be used for free in the above five agent frameworks, see below for detailed instructions. To call the Model API directly, see** [**Pricing and Rate Limits**](https://platform.xiaomimimo.com/#/docs/pricing) **for pricing standards.**
## 01 / OpenClaw
**Free for a Limited Time** — A Highly Anticipated General-Purpose Agent Framework. AI That Truly Gets Things Done.

#### Integration
Get an API Key from OpenRouter and configure it in your OpenClaw:
- In chat: `/model openrouter/xiaomi/mimo-v2-pro` (or v2-omni)
- In terminal: `openclaw models set openrouter/xiaomi/mimo-v2-pro` (or v2-omni)
- Or edit config: set `model.primary` to `openrouter/xiaomi/mimo-v2-pro` (or v2-omni)
See details on [OpenClaw provides free access to MiMo-V2-Pro/MiMo-V2-Omni replicas via Openrouter](https://platform.xiaomimimo.com/#/docs/integration/openclaw-with-openrouter) .

## 02 / OpenCode
**Free for a Limited Time** — Open-Source AI Coding Agent. 120K+ GitHub Stars. 5M+ Developers Monthly.

#### Integration
From the terminal, desktop app, or IDE extension, select MiMo V2 Pro / MiMo V2 Omni (FREE tag) under OpenCode → Zen.

## 03 / KiloCode
**Free for a Limited Time —** A Full-Featured AI Engineering Platform for Developers. 1M+ Kilo Developers.

#### Integration
From the terminal or IDE extension, select MiMo V2 Pro / MiMo V2 Omni (FREE tag) under Kilo Gateway.

## 04 / Cline
**Free for a Limited Time —** AI Coding Assistant That Helps Developers Build and Refactor High-Quality Software at 2x Speed.

#### Integration
From the terminal or IDE extension, select Cline as the Provider and choose mimo-v2-pro (FREE tag).

## 05 / BLACKBOX.AI
One of the Fastest-Growing Coding Agents Globally — Committed to Redefining How You Write Code with AI.
Blackbox.AI is Currently in Final Testing and Coming Soon. Stay Tuned to Blackbox.AI's Official X Posts.

#### Integration
Select the model in the terminal, desktop app, or IDE extension to integrate.

## 06 / MiMo-V2-TTS
**Free for an Extended Period.** — Xiaomi's In-House Text-to-Speech Foundation Model. Empowering Agents with Warm, Expressive, and Soulful Voice.
#### Integration
Access via the official API platform.
For detailed integration, refer to: [MiMo-V2-TTS Usage Guide](https://platform.xiaomimimo.com/#/docs/usage-guide/speech-synthesis)

AI Without Barriers. Innovation Without Limits. Global Developers — Unleash the Power of Trillion-Parameter Models Paired with Top-Tier Agent Frameworks.

--- DOCUMENT: Xiaomi MiMo-V2-Pro: Flagship Foundation Model towards Agent Era ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/v2-pro-release.md
# Xiaomi MiMo-V2-Pro: Flagship Foundation Model towards Agent Era
Today, we are releasing Xiaomi MiMo-V2-Pro, Xiaomi’s flagship foundation model for the agent era.
Xiaomi MiMo-V2-Pro is built for demanding real-world Agent workflows. It has over **1T** total parameters, with **42B** active parameters, uses an innovative hybrid attention architecture, and supports an ultra-long context window of up to **1M** tokens. Based on the strong foundation model, we continue to scale compute across a broader range of agent scenarios, further expanding the action space of intelligence and achieving an important generalization leap from Coding to Claw.
On the global authoritative model intelligence ranking by Artificial Analysis, MiMo-V2-Pro ranks eighth worldwide and second in China.

In agent frameworks such as OpenClaw and Claude Code, MiMo-V2-Pro shows excellent end-to-end task completion ability. It can handle complex workflow orchestration, long-horizon planning, and precise tool use without human intervention, while reliably delivering final results. In overall hands-on experience, it has surpassed Claude Sonnet 4.6 and is approaching Opus 4.6, while its API pricing is only one-fifth of theirs, lowering the barrier to using frontier intelligence.
## A major leap in foundation capabilities
By scaling both parameters and compute, MiMo-V2-Pro reaches to a larger and stronger model foundation.
- **Trillion-parameter scale, efficient architecture**: Total parameters exceed 1T, with 42B active parameters, about 3x larger than the previous MiMo-V2-Flash. It continues to use the innovative Hybrid Attention mechanism introduced in MiMo-V2-Flash, with the hybrid ratio further increased from 5:1 to 7:1. This keeps inference efficient even with the large increase in model size, while also supporting 1M-token context. A lightweight MTP (Multi-Token Prediction) layer enables fast generation.
- **From Chat to Agent**: By scaling during post-training across a broader set of Agent tasks, the model is no longer limited to “answering questions” or “generating polished demos.” It is built to complete tasks. We aim to integrate it deeply into productivity scenarios so it can serve as the “brain” behind working systems and continuously deliver results with real-world impact.
- **Real-world experience beyond benchmark rankings**: MiMo-V2-Pro performs strongly across benchmarks that measure key model capabilities. In Coding Agent, general Agent, and Tool Use tasks, it is in the same tier as Claude 4.5 Sonnet, GPT5.2, and Gemini 3.0 Pro, showing leading intelligence. We remain focused on training and optimization guided by actual user experience, always paying close attention to how the model performs in real applications.

## A flagship model built for Agents
MiMo-V2-Pro is deeply optimized specifically for Agent scenarios.
### The native brain for OpenClaw
OpenClaw is a general-purpose agent framework that has recently gained strong attention in the open-source community. As the core engine behind frameworks like this, the upper limit of the underlying model directly determines the system’s real-world performance. MiMo-V2-Pro is trained with SFT and RL on complex and diverse Agent scaffolds, giving it stronger tool-use and multi-step reasoning abilities.
On OpenClaw’s standard benchmark leaderboards, PinchBench and ClawEval, MiMo-V2-Pro ranks among the best in the world. At the same time, with its 1M-token context window, MiMo-V2-Pro can comfortably support demanding real-world Claw application flows. Hunter Alpha shown below is an early anonymous version of MiMo-V2-Pro.

### Continuous Evolution of Coding Capabilities
Going beyond mere "Vibe Coding", MiMo-V2-Pro is capable of participating in more rigorous code engineering construction.
In in-depth evaluations by internal engineers at Xiaomi, MiMo-V2-Pro's user experience has approached that of Claude Opus 4.6, demonstrating advanced code intelligence: it boasts superior system design and task planning capabilities, more elegant coding styles, and more efficient, direct problem-solving pathways.
During the "Hunter Alpha" anonymous testing phase, the most frequently called apps were mostly programming-specific tools, which confirm MiMo-V2-Pro's high usability and reliability in real-world R&D scenarios.

## 1M Context Window, Open API
The MiMo-V2-Pro model is now officially available via API with pricing:
- Within 256K: Input at $1 / 1M tokens, Output at $3 / 1M tokens
- 256K ~ 1M: Input at $2 / 1M tokens, Output at $6 / 1M tokens
Visit [https://platform.xiaomimimo.com](https://platform.xiaomimimo.com/) to get started.
--- DOCUMENT: Xiaomi MiMo-V2-Omni: Omni-Modal Agentic Foundation Model that Sees, Understands and Acts ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/v2-omni-release.md
# Xiaomi MiMo-V2-Omni: Omni-Modal Agentic Foundation Model that Sees, Understands and Acts
Today, we are thrilled to announce Xiaomi’s omni‑modal foundation model for agent era: Xiaomi MiMo‑V2‑Omni.
Designed specifically for complex real‑world multimodal interaction and execution scenarios, MiMo‑V2‑Omni is built from the ground up as a unified all‑modal foundation that integrates text, vision, and speech. Its unified architecture deeply binds perception and action, overcoming the traditional limitation of models that prioritize understanding over execution.
Natively equipped with multimodal perception, tool invocation, function execution, and GUI operation capabilities, MiMo‑V2‑Omni seamlessly integrates with major agent frameworks. It enables a true leap from understanding to control, drastically lowering the barrier to deploying all‑modal agents.
## Perception Capabilities: Image, Video, and Audio on the Frontier
Accurate perception is the prerequisite for action. We benchmarked MiMo-V2-Omni against leading international models across all sensory modalities to ensure a rock-solid foundation for its capabilities as an AI agent.
**Visual Understanding**: MiMo-V2-Omni demonstrates robust multidisciplinary visual reasoning and complex chart analysis. It has surpassed Claude 4.6 Opus and is rapidly closing the gap with top-tier closed-source models like Gemini 3.
**Audio Understanding**: The model supports everything from environmental sound classification and multi-speaker separation to audio-visual joint reasoning and deep comprehension of continuous audio exceeding 10 hours. Its comprehensive performance exceeds Gemini 3 Pro, making it one of the most powerful audio understanding base models currently available.
**Video Understanding**: By supporting native audio-video joint input, we have achieved true multimodal video comprehension. Through innovative video pre-training, the model possesses powerful situational awareness and predictive reasoning capabilities.
When multiple modalities are processed simultaneously, the advantages of a unified architecture are magnified: cross-modal signals mutually reinforce one another rather than competing for resources.
## Agentic Capabilities: from Understanding to Execution
If perception is the foundation, then action is the ultimate goal.
A true AI agent model must be capable of observing complex environments across multiple modalities, formulating and executing plans, autonomously recovering from errors, and delivering end-to-end results.
### Omni-Modal Agent Tasks
MiMo-V2-Omni excels in benchmarks involving interaction with real-world digital environments, performing on par with Gemini 3 Pro. This success is underpinned by its industry-leading perceptual capabilities:The more accurate the perception, the more effective execution.

At the same time, MiMo-V2-Omni remains highly competitive in text-only agent tasks.

## Capabilities Demonstration
### 💻 Browser-Use Scenarios
Browser Use is the ultimate litmus test for a model’s agentic capabilities. It involves real-world interactions, dynamic web environments, heterogeneous interaction methods, and active anti-automation mechanisms. In these scenarios, the closed loop of perception, decision-making, and action operates continuously in an open environment until the mission is accomplished. When these same capabilities are ported to smart devices or robotics, they form the blueprint for General-Purpose Agents.
- **Shopping, Bargaining, and Ordering on Your Behalf**
We tested an end-to-end shopping task. Controlling the browser, the model first browsed over a dozen posts on Xiaohongshu to complete information gathering and obtain purchasing recommendations. It then performed cross-platform price comparisons across multiple stores on JD, followed by connecting with human customer service to bargain using natural language. After real-time interaction with the representative, it ultimately completed the process of adding items to the cart and placing the order. The model autonomously handled non-standard DOM structures, multi-tab context management, and workflow recovery after encountering platform anti-automation detections.
- **TikTok Video Creation and Publishing**
We tested an end-to-end video publishing task. The model autonomously designed four sets of visuals and synthesized all sound effects on-site with zero reliance on external assets. During rendering, it encountered a Chinese font error, which it self-corrected before continuing. It then controlled the browser to open the TikTok upload page, analyzed non-standard input controls to complete the copywriting, and proceeded to like and comment after clicking "Publish." Finally, it re-checked to confirm the video passed review and was publicly live.
### 🗒️ Smart Office Scenarios
Through natural dialogue, MiMo-V2-Omni can directly generate high-quality Word documents, structured Excel sheets, professionally formatted PDFs, and complete PPTs. These generated documents are no longer drafts requiring heavy revision, but high-quality "near-final versions" tailored to actual needs.
- **2026 Intelligent College Entrance Examination Application**
We tested the college entrance examination application planning task. The model can autonomously initiate web searches to obtain raw information, use skills to process files, and generate an Excel spreadsheet containing detailed application recommendations and tiered classifications.
## Open API
The MiMo-V2-Omni model is now officially available via API with pricing:
- Input: $0.4 / million tokens;
- Output: $2 / million tokens.
Visit [https://platform.xiaomimimo.com](https://platform.xiaomimimo.com/) to get started.
--- DOCUMENT: Xiaomi MiMo-V2-TTS: Versatile Voice Agent that Speaks and Sings ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/v2-tts-release.md
# Xiaomi MiMo-V2-TTS: Versatile Voice Agent that Speaks and Sings
**Xiaomi MiMo-V2-TTS** is a large-scale speech synthesis model independently developed by Xiaomi. Built on a proprietary audio tokenizer and a multi-codebook joint speech–text modeling architecture, it has been trained on hundreds of millions of hours of speech data with large-scale pretraining and multi-dimensional reinforcement learning, enabling highly controllable, fine-grained speech style generation. MiMo-V2-TTS supports precise control ranging from global style setting to nuanced local emotional expression. It can perform tone shifts and gradual emotional transitions within a single utterance, faithfully reproducing the natural prosody of human speech. When singing, it can also accurately render pitch and rhythm, delivering natural and expressive performance.
The MiMo-V2-TTS model is now available through the Xiaomi MiMo API open platform (https://platform.xiaomimimo.com), **with free access for a limited time**.
### Text Control
Flexible and customizable style control
MiMo-V2-TTS supports free-form natural language descriptions instead of being limited to predefined keywords. The model can understand and follow arbitrary descriptive instructions.
- Emotion control: happy, sad, angry, gentle, excited, calm…
- Dialect support: Northeastern Mandarin, Sichuan dialect, Henan dialect, Cantonese, Taiwanese accent…
- Role play: Monkey King, Lin Daiyu, Iron Man…
- Freely combined phrases — true natural language control: “cute and coquettish, soft ‘baby voice’,” “lazy, just woke up, slightly husky,” “deeply affectionate, slow speaking pace,” “passionate and powerful”
### Fine-grained control of vocal events
MiMo-V2-TTS can naturally insert and control various paralinguistic vocal events in speech, making the generated audio more realistic and expressive.
Supported vocal events: laughter, coughing, pauses, thinking/hesitation, sighing, etc.
## Deep Text Understanding
The model can intelligently recognize formatting cues in text and convert them into corresponding speech expressions—such as tone and punctuation—without requiring extra annotations.
Format awareness → speech rendering:
- ALL CAPS text (e.g., “THIS IS IMPORTANT”) → automatically adds emphasis;
- Repeated words or characters (e.g., “no no no no no”) → automatically mapped to matching rhythm and emotion.
During pretraining, the model learned from large-scale text–speech aligned data, enabling it to convert written formatting signals into natural-sounding speech.
## Beyond Speech: Dialects · Characters · Singing
MiMo-V2-TTS goes beyond standard speech synthesis with rich and versatile expressive capabilities. It supports natural pronunciation across multiple dialects, enables role-playing with stylized character performances, and delivers high-quality singing synthesis—allowing a single model to speak, act, and sing with ease.
## Open API
MiMo-V2-TTS is now officially available via API. **Free access is available for a limited time.**
Visit [https://platform.xiaomimimo.com](https://platform.xiaomimimo.com/) to get started.
--- DOCUMENT: MiMo-V2-Flash Release Note 2026/03/03 ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/news20260303.md
# MiMo-V2-Flash Release Note 2026/03/03
MiMo-V2-Flash now supports web search, enabling access to real-time public information (such as news, products, weather, etc.).
**Core Capabilities**
- **Flexible search modes**: Supports forced search and intent recognition. With intent recognition enabled, the model will autonomously decide whether to perform an online search without manual triggering.
- **Early search source return**: In the streaming response, the first packet will return all search sources.
- **Hybrid multi-tool invocation**: Can work with custom functions and tools; the model will automatically determine invocation priority and necessity.
- **Flexible response modes**: Supports both streaming and non-streaming responses, and both methods will return search and summary content.
**Use Cases**
- **Real-Time News Aggregation**
- Scenario: A user asks, "What are today's top stories about domestic large language models?"
- Capability: The model automatically generates search keywords like "Chinese LLM latest news March 1 2026," searches the web, and returns a summarized response with source links.
- **Product Information & Price Comparison**
- Scenario: A user asks, "What are the price and user reviews for the latest model of [Brand] phone?"
- Capability: The model searches multiple e-commerce platforms for pricing and reviews, then organizes the information into a concise summary to aid decision-making.
- **Real-Time Weather & Travel Information**
- Scenario: A user asks, "Is the weather in Shanghai tomorrow good for going out?"
- Capability: The model fetches the Shanghai weather forecast and provides practical suggestions based on common sense, such as "Rain expected tomorrow in Shanghai, temperatures 10–15°C. Bring an umbrella and dress warmly."
**Instructions and Recommendations**
1. **Enable Web Search Plugin**: Before using this feature, you need to activate the [Web Search Plugin](https://platform.xiaomimimo.com/#/console/plugin). For detailed parameters and invocation instructions, please refer to the [OpenAI API](https://platform.xiaomimimo.com/#/docs/api/text-generation/openai-api).
1. **Fees**: The web search feature incurs additional token consumption for generating search queries and processing results. A separate fee will also be charged per search call. For details, see [Web Search](https://platform.xiaomimimo.com/#/docs/usage-guide/tool-calling/web-search).
--- DOCUMENT: MiMo-V2-Flash Release Note 2026/02/04 ---
URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/news20260212.md
# MiMo-V2-Flash Release Note 2026/02/04
1. **Upgraded Coding Capabilities in Thinking Mode:**
Specifically optimized for programming scenarios, the Thinking Mode now achieves a score of **78.6** on SWE-Bench Verified. Both the resolution rate and the quality of code generation have been significantly improved.
1. **Substantial Boost in Tool Calling Accuracy:**
Stability issues regarding tool usage have been resolved. Tool calling accuracy in Thinking Mode has surged from 64% to **97.0%**, greatly enhancing execution reliability in Agent scenarios.
1. **Enhanced Instruction Following & Reduced Hallucinations:**
- **Instruction Following:** Improved adherence to specific instructions, achieving an **AA-IFBench score of 72**.
- **Factuality:** Enhanced rigor in factual responses, with the **Non-Hallucination Rate updated to 52%**.
1. **Optimized Handling of Complex Tasks:**
Performance on Arena-Hard (Hard Prompts) in Thinking Mode has been strengthened, with the score rising to **60.6**. The model now demonstrates superior performance when handling high-difficulty logic problems.
1. **More Efficient Chain-of-Thought (CoT):**
By optimizing CoT generation strategies, the consumption of redundant tokens has been significantly reduced. In benchmarks such as AIME25 and HMMT, the average generation length has decreased by **13% to 30%**. This effectively lowers latency and token costs while maintaining model performance.
| | **MiMo-V2-Flash-0204** | **MiMo-V2-Flash-0112** | **MiMo-V2-Flash** |
| --- | --- | --- | --- |
| **SWE-Bench Verified** **—— Xiaomi MiMo API Open Platform Team**
**January 23, 2026**
--- DOCUMENT: Xiaomi MiMo API Open Platform Recharge Function Officially Launched --- URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/recharge.md # Xiaomi MiMo API Open Platform Recharge Function Officially Launched ## Dear Developers, Thank you for your continuous support of the Xiaomi MiMo API Open Platform. We are pleased to announce that the recharge service is now officially available as of **January 20, 2026**. To ensure the continuity of your service, we recommend completing your account recharge in advance to avoid any service interruptions due to insufficient balance after the billing system goes live. ### MiMo-V2-Flash API Pricing - **China**: Input: ¥0.7 / 1M tokens, Cached Input: ¥0.07 / 1M tokens, Output: ¥2.1 / 1M tokens - **Overseas**: Input: $0.1 / 1M tokens, Cached Input: $0.01 / 1M tokens, Output: $0.3 / 1M tokens ### Exclusive Benefits Available To thank you for your support, we have prepared exclusive free credits for all new and existing users. You can log in and go to [Balance](https://platform.xiaomimimo.com/#/console/balance) to collect them. ### About the Billing System Our billing system will officially launch in the near future. The exact date will be announced in an official announcement. Until then, API calls will remain free—your topped-up balance and free credits won’t be deducted for now. ### Recharge Rules 1. **Real-Name Authentication**: Chinese mainland users must complete individual real-name authentication before recharging. Enterprise authentication is not yet available; please stay tuned for updates. Other users can recharge directly without real-name authentication. 1. **Recharge Process**: Go to the [Balance](https://platform.xiaomimimo.com/#/console/balance) page to recharge. Chinese mainland users can use Xiaomi Pay, Alipay, or WeChat Pay. Other users can use common payment methods such as Apple Pay, Google Pay, and credit/debit cards. 1. **Balance Inquiry**: Recharged funds are generally credited to your account in real time. You can view recharge orders and bonus amounts on the [Recharge Details](https://platform.xiaomimimo.com/#/console/recharge) page, and check your current balance on the [Balance](https://platform.xiaomimimo.com/#/console/balance) page. Once the billing system is activated, API calls will first deduct the complimentary free quota, followed by the recharged balance. 1. **Invoice Issuance**: Chinese mainland users can apply for electronic invoices by selecting successful recharge orders on the [Invoice](https://platform.xiaomimimo.com/#/console/invoice) page. Other users can download order receipts from the [Recharge Details](https://platform.xiaomimimo.com/#/console/recharge) page. 1. **For more details, please refer to** [FAQ](https://platform.xiaomimimo.com/#/docs/faq?target=payment-issue). ### Contact Us For assistance or business inquiries, feel free to reach out to us through the following channels: - Email: support-mimo@xiaomi.com - Scan the QR code at the bottom left to join the developer communication group - Submit your feedback from [Contact Us](https://platform.xiaomimimo.com/#/contact) We are committed to continuously optimizing our products and services to provide you with superior AI capabilities. Thank you again for your understanding and trust!**—— Xiaomi MiMo API Open Platform Team**
**January 20, 2026**
--- DOCUMENT: MiMo-V2-Flash Release Note 2026/01/12 --- URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/news20260112.md # MiMo-V2-Flash Release Note 2026/01/12 1. **Enhanced general capabilities:** Improved the model’s performance on a wide range of general-purpose tasks. 1. **Upgraded coding performance in Thinking mode:** Strengthened code generation quality in Thinking mode, especially for programming scenarios. 1. **Deep integration with Claude Code:** Fully supports using Thinking mode in Claude Code. - **Best practice:** Set Thinking as the default mode to achieve more stable, higher-quality code generation. 1. **Optimized Experience for Other Code Agents:** Synchronized improvements to the interaction experience and generation quality across code assistant tools (Code Scaffolds) such as Kilo, Cline, and Roo. 1. **Improved Stability & Instruction Following:** Enhanced output stability and significantly improved adherence to specific output formats. | | **MiMo-v2-Flash-0112** | **MiMo-v2-Flash** | | --- | --- | --- | | **SWE-Bench Verified****—— Xiaomi MiMo API Open Platform Team**
--- DOCUMENT: MiMo-V2-Flash Release 2025/12/16 --- URL: https://platform.xiaomimimo.com/static/docs/news/previous-news/news20251216.md # MiMo-V2-Flash: High-Efficiency Inference, Code & Agent Foundation Model Xiaomi MiMo-V2-Flash is officially open-sourced today!!! It is a MoE (Mixture of Experts) model designed for extreme inference efficiency, with 309B total and 15B activated parameters. With an innovative hybrid attention and multi-layer MTP (Multi-Token Prediction) architecture, the model ranks **top 2 among all open-source models** across multiple agent evaluation benchmarks. Besides, its coding capability surpasses all open-source models and is comparable with Claude 4.5 Sonnet, while its **inference cost is only 2.5%** of Claude’s and its **generation speed is doubled** — pushing inference efficiency to the limit. 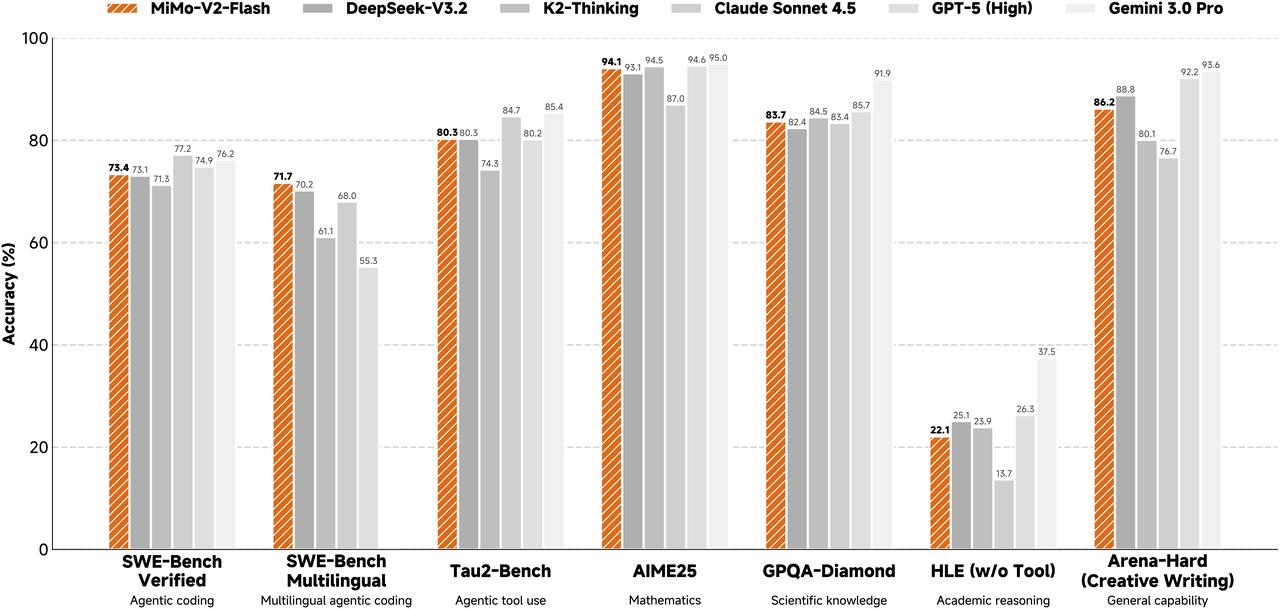 To foster open-source engagement, both the model weights and inference code are fully open-sourced under the MIT license. **The API is available free of charge for a limited time.** ## Extreme Optimization of Cost and Speed The API pricing for MiMo-V2-Flash is **$0.1 per million input tokens and $0.3 per million output tokens.** In the chart below, the horizontal axis compares speed and cost across leading models——MiMo-V2-Flash achieves both the lowest cost and the highest speed. 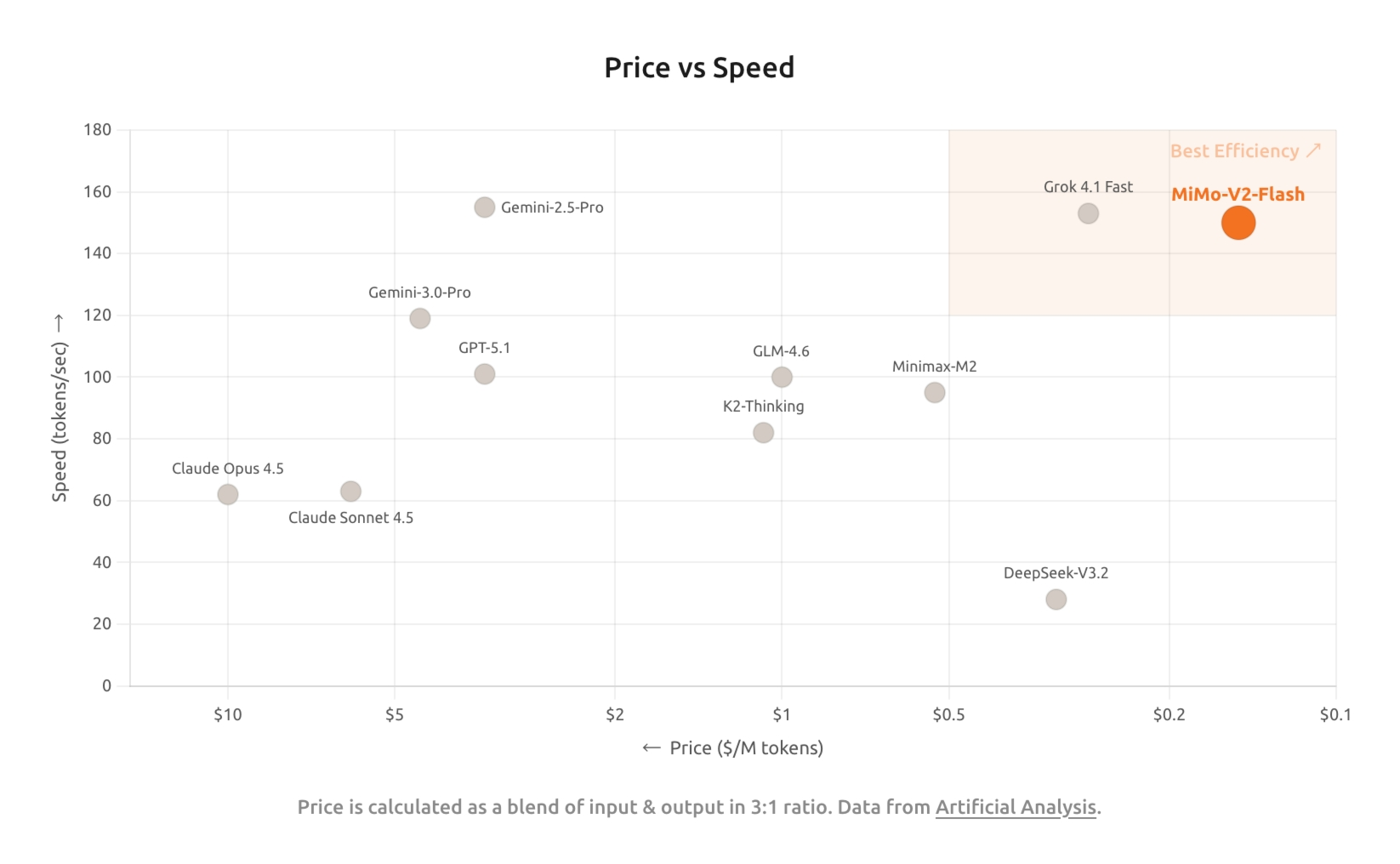 ## Architectural innovations designed for high-efficiency inference Key architectural designs: - **Hybrid Attention:** We adopt a hybrid attention mechanism combining Global Attention and Sliding Window Attention (SWA) at a 1:5 ratio, where the window size of SWA is 128. During pre-training, we train the model with a context length of 32k, and extend it to 256k. Compared to mainstream Linear Attention approaches, extensive early-stage empirical studies show that SWA is simple, efficient, and practical, delivering stronger overall performance in general tasks, long-context handling, and reasoning. It also provides a fixed-size KV cache, making it easy to integrate with existing training and inference infrastructure. 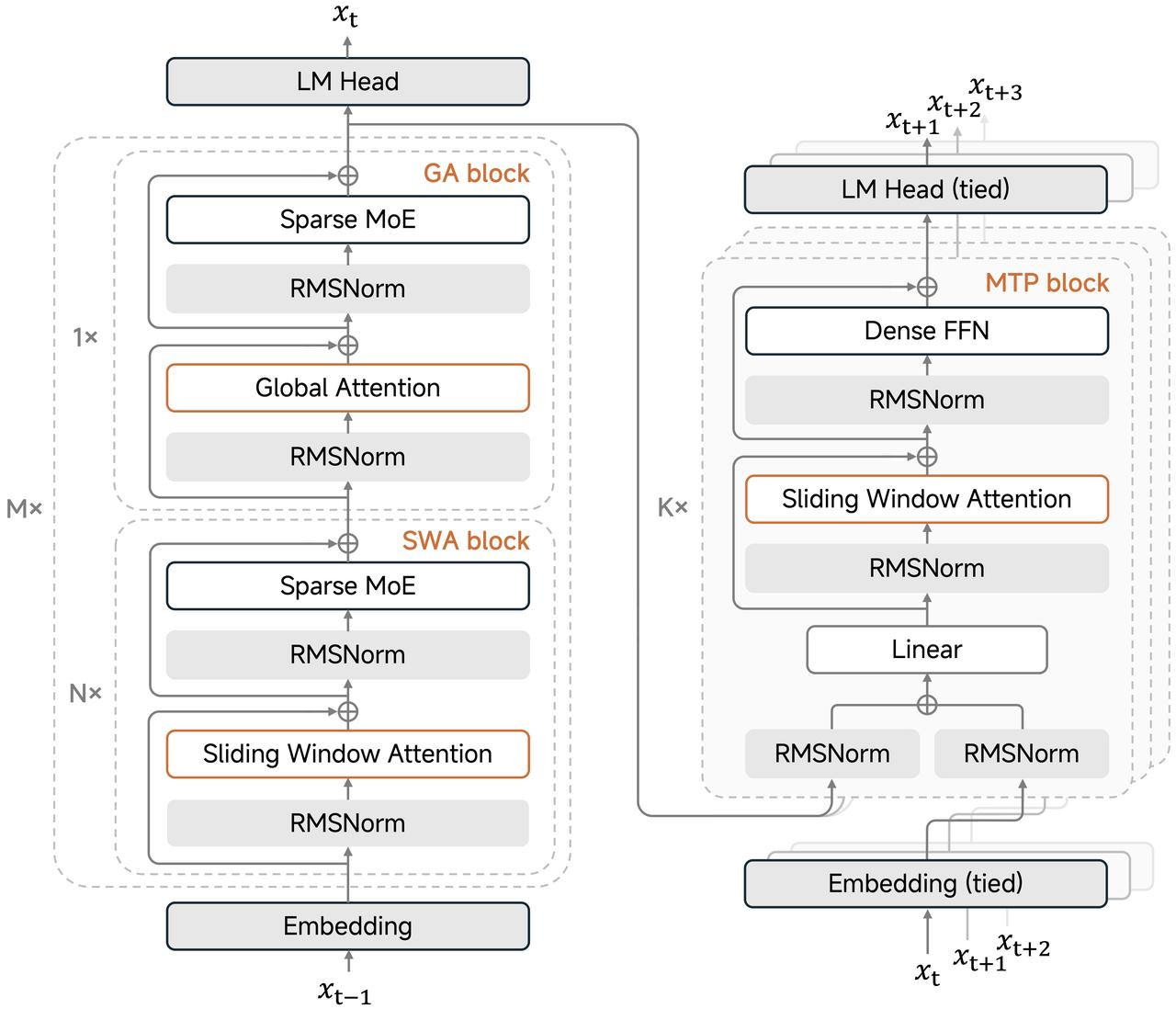 - **MTP Inference Acceleration**: We introduce MTP (Multi-Token Prediction) to strengthen the model's capability and speed up inference. During inference, MTP validates MTP tokens in parallel, breaking the memory bandwidth bottleneck of traditional decoding under large batch sizes. In practice, a 2.5×–3.7× real-world speedup is achieved with a 3-layer MTP setup.  ## Related links - Technical Report:[https://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf](https://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf) - Model Weights:https://hf.co/XiaomiMiMo/MiMo-V2-Flash - Github Repository:https://github.com/xiaomimimo/MiMo-V2-Flash - Blog Post: https://mimo.xiaomi.com/blog/mimo-v2-flash - LMSYS Blog:[https://lmsys.org/blog/2025-12-16-mimo-v2-flash](https://lmsys.org/blog/2025-12-16-mimo-v2-flash/) --- DOCUMENT: OpenAI API --- URL: https://platform.xiaomimimo.com/static/docs/api/chat/openai-api.md # OpenAI API Compatibility ## Request Address ```bash https://api.xiaomimimo.com/v1/chat/completions ``` ## Request Headers The API supports the following two authentication methods. Please choose one and add it to the request headers: 1. Method 1: `api-key` field authentication, format: ```json api-key: $MIMO_API_KEY Content-Type: application/json ``` 1. Method 2: `Authorization: Bearer` authentication, format: ```json Authorization: Bearer $MIMO_API_KEY Content-Type: application/json ``` ## Request bodydeveloper"
},
{
"name": "name",
"type": "string",
"isBold": true,
"required": false,
"description": "An optional name for the participant. Provides the model information to differentiate between participants of the same role."
}
]
},
{
"name": "System message",
"type": "object",
"isBold": false,
"description": "Developer-provided instructions that the model should follow, regardless of messages sent by the user.",
"children": [
{
"name": "content",
"type": [
"string",
"array"
],
"isBold": true,
"required": true,
"description": "The contents of the system message.",
"children": [
{
"name": "Text content",
"type": "string",
"isBold": false,
"description": "The contents of the system message."
},
{
"name": "Array of content parts",
"type": "array",
"isBold": false,
"description": "An array of content parts with a defined type. For system messages, only type text is supported.",
"children": [
{
"name": "Text content part",
"type": "object",
"isBold": false,
"children": [
{
"name": "text",
"type": "string",
"isBold": true,
"required": true,
"description": "The text content."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content part."
}
]
}
]
}
]
},
{
"name": "role",
"type": "string",
"isBold": true,
"required": true,
"description": "Role of the message author.system"
},
{
"name": "name",
"type": "string",
"isBold": true,
"required": false,
"description": "An optional name for the participant. Provides the model information to differentiate between participants of the same role."
}
]
},
{
"name": "User message",
"type": "object",
"isBold": false,
"description": "Messages sent by an end user, containing prompts or additional context information.",
"children": [
{
"name": "content",
"type": [
"string",
"array"
],
"isBold": true,
"required": true,
"description": "The contents of the user message.Note: When generating audio using the", "children": [ { "name": "Text content", "type": "string", "isBold": false, "description": "The text contents of the message." }, { "name": "Array of content parts", "type": "array", "isBold": false, "description": "An array of content parts with a defined type. Supported options differ based on the model being used to generate the response. Can contain text, image, audio or video inputs.mimo-v2.5-tts-voicedesignmodel, messages with roleuserare required. You may provide anassistantrole message to specify the text for audio synthesis. Ifoptimize_text_previewis set totrue, theassistantmessage can be omitted. Moreover, audio parameters can be configured viaaudio. For detailed usage, please refer to Speech Synthesis.
Currently, only the", "children": [ { "name": "Text content part", "type": "object", "isBold": false, "children": [ { "name": "text", "type": "string", "isBold": true, "required": true, "description": "The text content." }, { "name": "type", "type": "string", "isBold": true, "required": true, "description": "The type of the content part." } ] }, { "name": "Image content part", "type": "object", "isBold": false, "children": [ { "name": "image_url", "type": "object", "isBold": true, "required": true, "children": [ { "name": "url", "type": "string", "isBold": true, "required": true, "description": "Either a URL of the image or the base64 encoded image data." } ] }, { "name": "type", "type": "string", "isBold": true, "required": true, "description": "The type of the content part.mimo-v2.5andmimo-v2-omnimodels support image, audio, or video input.
image_url"
}
]
},
{
"name": "Audio content part",
"type": "object",
"isBold": false,
"children": [
{
"name": "input_audio",
"type": "object",
"isBold": true,
"required": true,
"children": [
{
"name": "data",
"type": "string",
"isBold": true,
"required": true,
"description": "Either a URL of the audio or the base64 encoded audio data."
}
]
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content part.input_audio"
}
]
},
{
"name": "Video content part",
"type": "object",
"isBold": false,
"children": [
{
"name": "video_url",
"type": "object",
"isBold": true,
"required": true,
"children": [
{
"name": "url",
"type": "string",
"isBold": true,
"required": true,
"description": "Either a URL of the video or the base64 encoded video data."
}
]
},
{
"name": "fps",
"type": "number",
"isBold": true,
"required": false,
"defaultValue": "2",
"description": "Number of frames sampled per second.[0.1, 10.0]"
},
{
"name": "media_resolution",
"type": "string",
"isBold": true,
"required": false,
"defaultValue": "default",
"description": "Resolution level.default, max"
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content part.video_url"
}
]
}
]
}
]
},
{
"name": "role",
"type": "string",
"isBold": true,
"required": true,
"description": "Role of the message author.user"
},
{
"name": "name",
"type": "string",
"isBold": true,
"required": false,
"description": "An optional name for the participant. Provides model information to differentiate between participants of the same role."
}
]
},
{
"name": "Assistant message",
"type": "object",
"isBold": false,
"description": "Messages sent by the model in response to user messages.",
"children": [
{
"name": "role",
"type": "string",
"isBold": true,
"required": true,
"description": "Role of the message author.assistant"
},
{
"name": "content",
"type": [
"string",
"array"
],
"isBold": true,
"required": false,
"description": "The contents of the assistant message. Required unless tool_calls is specified.Note: To generate audio, you must add a message with role set to", "children": [ { "name": "Text content", "type": "string", "isBold": false, "description": "The contents of the assistant message." }, { "name": "Array of content parts", "type": "array", "isBold": false, "description": "An array of content parts with a defined type. Can be one or more of typeassistant, which needs to specify the text for speech synthesis. When using themimo-v2.5-tts-voicedesignmodel, a message with the role ofuseris required. Ifoptimize_text_previewis set totrue, theassistantmessage can be omitted. Additionally, audio parameters can be configured viaaudio. For detailed usage, please refer to Speech Synthesis.
text.",
"children": [
{
"name": "Text content part",
"type": "object",
"isBold": false,
"children": [
{
"name": "text",
"type": "string",
"isBold": true,
"required": true,
"description": "The text content."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content part."
}
]
}
]
}
]
},
{
"name": "name",
"type": "string",
"isBold": true,
"required": false,
"description": "An optional name for the participant. Provides model information to differentiate between participants of the same role."
},
{
"name": "tool_calls",
"type": "array",
"isBold": true,
"required": false,
"description": "The tool calls generated by the model, such as function calls.",
"children": [
{
"name": "Function tool call",
"type": "object",
"isBold": false,
"description": "A call to a function tool created by the model.",
"children": [
{
"name": "function",
"type": "object",
"isBold": true,
"required": true,
"description": "The function that the model called.",
"children": [
{
"name": "arguments",
"type": "string",
"isBold": true,
"required": true,
"description": "The arguments to call the function with, as generated by the model in JSON format. Note that the model does not always generate valid JSON, and may hallucinate parameters not defined by your function schema. Validate the arguments in your code before calling your function."
},
{
"name": "name",
"type": "string",
"isBold": true,
"required": true,
"description": "The name of the function to call."
}
]
},
{
"name": "id",
"type": "string",
"isBold": true,
"required": true,
"description": "The ID of the tool call."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "Tool type. Currently, only function is supported."
}
]
}
]
}
]
},
{
"name": "Tool message",
"type": "object",
"isBold": false,
"children": [
{
"name": "content",
"type": [
"string",
"array"
],
"isBold": true,
"required": true,
"description": "The contents of the tool message.",
"children": [
{
"name": "Text content",
"type": "string",
"isBold": false,
"description": "The contents of the tool message."
},
{
"name": "Array of content parts",
"type": "array",
"isBold": false,
"description": "An array of content parts with a defined type. For tool messages, only type text is supported.",
"children": [
{
"name": "Text content part",
"type": "object",
"isBold": false,
"children": [
{
"name": "text",
"type": "string",
"isBold": true,
"required": true,
"description": "The text content."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content part."
}
]
}
]
}
]
},
{
"name": "role",
"type": "string",
"isBold": true,
"required": true,
"description": "Role of the message author.tool"
},
{
"name": "tool_call_id",
"type": "string",
"isBold": true,
"required": true,
"description": "Tool call that this message is responding to."
}
]
}
]
},
{
"name": "model",
"type": "string",
"isBold": true,
"required": true,
"description": "Model ID is used to generate the response.mimo-v2.5-pro, mimo-v2.5, mimo-v2.5-tts, mimo-v2.5-tts-voicedesign, mimo-v2.5-tts-voiceclone, mimo-v2-pro, mimo-v2-omni, mimo-v2-tts, mimo-v2-flash"
},
{
"name": "audio",
"type": "object",
"isBold": true,
"required": false,
"description": "Parameters for audio output. For details, please refer to Speech Synthesis.Note: To generate audio, you must add a message with role set toassistant, which needs to specify the text for speech synthesis. Additionally, when using themimo-v2.5-tts-voicedesignmodel, a message with the role ofuseris required. Ifoptimize_text_previewis set totrue, theassistantmessage can be omitted. For detailed usage, please refer to Speech Synthesis.
Currently, only the", "children": [ { "name": "format", "type": "string", "isBold": true, "required": false, "defaultValue": "wav", "description": "Specifies the output audio format. Default:mimo-v2.5-tts,mimo-v2.5-tts-voicedesign,mimo-v2.5-tts-voicecloneandmimo-v2-ttsmodels are supported.
wav, or pcm when you set stream: true.Passing inAvailable options:pcmorpcm16both indicate specifying the use of thepcm16format.
wav, mp3, pcm, pcm16"
},
{
"name": "optimize_text_preview",
"type": "boolean",
"isBold": true,
"required": false,
"defaultValue": "false",
"description": "Enables intelligent optimization of the target audio broadcast text.true, the input target text is intelligently polished; if no target text is provided, a broadcast-adapted target text is automatically generated. The finalized processed text is then fed into the model for speech synthesis.Note: When this parameter is set totrue, theassistantrole message for specifying speech synthesis content can be omitted.
Currently, only the mimo-v2.5-tts-voicedesign model is supported."
},
{
"name": "voice",
"type": "string",
"isBold": true,
"description": "The voice ID of the built-in voice or the base64 encoding of the audio sample.mimo-v2.5-tts, mimo-v2-tts: This field is optional and only supports using built-in voices, with the default value being mimo_defaultmimo-v2.5-tts-voiceclone: This field is required and only supports passing in the base64 encoding of audio samples, and only supports passing in audio sample files in mp3 and wav formatsmimo-v2.5-tts-voicedesign does not support this fieldmimo-v2-tts: mimo_default, default_en, default_zhmimo-v2.5-tts: mimo_default, 冰糖, 茉莉, 苏打, 白桦, Mia, Chloe, Milo, Dean[-2.0, 2.0]"
},
{
"name": "max_completion_tokens",
"type": [
"integer",
"null"
],
"isBold": true,
"required": false,
"description": "An upper bound for the number of tokens that can be generated for a completion, including visible output tokens and reasoning tokens.mimo-v2-flash: default 65536mimo-v2.5-pro, mimo-v2-pro: default 131072mimo-v2.5, mimo-v2-omni: default 32768mimo-v2.5-tts, mimo-v2.5-tts-voiceclone, mimo-v2.5-tts-voicedesign, mimo-v2-tts: default 8192, required range is [1, 8192][1, 131072]"
},
{
"name": "presence_penalty",
"type": [
"number",
"null"
],
"isBold": true,
"required": false,
"defaultValue": "0",
"description": "Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics.[-2.0, 2.0]"
},
{
"name": "response_format",
"type": "object",
"isBold": true,
"required": false,
"description": "An object specifying the format that the model must output.", "children": [ { "name": "Text", "type": "object", "isBold": false, "description": "Default response format. Used to generate text responses.", "children": [ { "name": "type", "type": "string", "isBold": true, "required": true, "description": "The type of response format being defined. Alwaysmimo-v2.5-tts,mimo-v2.5-tts-voicedesign,mimo-v2.5-tts-voicecloneandmimo-v2-ttsmodels are not supported.
text."
}
]
},
{
"name": "JSON object",
"type": "object",
"isBold": false,
"description": "JSON object response format. Note that the model will not generate JSON without a system or user message instructing it to do so.",
"children": [
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of response format being defined. Always json_object."
}
]
}
]
},
{
"name": "stop",
"type": [
"string",
"array",
"null"
],
"isBold": true,
"required": false,
"defaultValue": "null",
"description": "Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence." }, { "name": "stream", "type": [ "boolean", "null" ], "isBold": true, "required": false, "defaultValue": "false", "description": "If set to true, the model response data will be streamed to the client as it is generated using server-sent events." }, { "name": "thinking", "type": "object", "isBold": true, "required": false, "description": "This parameter is used to control whether the model enables the chain of thought.mimo-v2.5-tts,mimo-v2.5-tts-voicedesign,mimo-v2.5-tts-voicecloneandmimo-v2-ttsmodels are not supported.
Note: During the multi-turn tool calls process in thinking mode, the model returns areasoning_contentfield alongsidetool_calls. To continue the conversation, it is recommended to keep all previousreasoning_contentin themessagesarray for each subsequent request to achieve the best performance.
In thinking mode, themimo-v2.5-proandmimo-v2.5models do not support customizing thetemperatureparameter. Even if this parameter is passed in, it will be forcibly overridden and take effect with the model's recommended default value of1.0.
", "children": [ { "name": "type", "type": "string", "isBold": true, "required": true, "description": "Whether to enable the chain of thought.mimo-v2.5-tts,mimo-v2.5-tts-voicedesign,mimo-v2.5-tts-voicecloneandmimo-v2-ttsmodels are not supported.
mimo-v2-flash: default disabledmimo-v2.5-pro, mimo-v2.5, mimo-v2-pro, mimo-v2-omni: default enabledenabled, disabled"
}
]
},
{
"name": "temperature",
"type": "number",
"isBold": true,
"required": false,
"description": "What sampling temperature to use, between 0 and 1.5. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. We generally recommend altering this or top_p but not both.In thinking mode, themimo-v2.5-proandmimo-v2.5models do not support customizing thetemperatureparameter. Even if this parameter is passed in, it will be forcibly overridden and take effect with the model's recommended default value of1.0.
mimo-v2-flash: default 0.3mimo-v2.5-pro, mimo-v2.5, mimo-v2-pro, mimo-v2-omni: default 1.0mimo-v2.5-tts, mimo-v2.5-tts-voiceclone, mimo-v2.5-tts-voicedesign, mimo-v2-tts: default 0.6[0, 1.5]"
},
{
"name": "tool_choice",
"type": "string",
"isBold": true,
"required": false,
"description": "Controls how the model selects a tool.Note: When a value other thanautois passed totool_choice, the backend will remove this field by default, and the model response behavior will still be equivalent to theautomode (this logic is subject to future adjustments).
Available options:mimo-v2.5-tts,mimo-v2.5-tts-voicedesign,mimo-v2.5-tts-voicecloneandmimo-v2-ttsmodels are not supported.
auto"
},
{
"name": "tools",
"type": "array",
"isBold": true,
"required": false,
"description": "A list of tools the model may call. You can provide function tools.Note: During the multi-turn tool calls process in thinking mode, the model returns areasoning_contentfield alongsidetool_calls. To continue the conversation, it is recommended to keep all previousreasoning_contentin themessagesarray for each subsequent request to achieve the best performance.
", "children": [ { "name": "Function tool", "type": "object", "isBold": false, "description": "A function tool that can be used to generate a response.", "children": [ { "name": "function", "type": "object", "isBold": true, "required": true, "children": [ { "name": "name", "type": "string", "isBold": true, "required": true, "description": "The name of the tool function. Must bemimo-v2.5-tts,mimo-v2.5-tts-voicedesign,mimo-v2.5-tts-voicecloneandmimo-v2-ttsmodels are not supported.
a-z, A-Z, 0-9, or contain underscores (_) and dashes (-), with a maximum length of 64.1 - 64"
},
{
"name": "description",
"type": "string",
"isBold": true,
"required": false,
"description": "A description of what the function does, used by the model to choose when and how to call the function."
},
{
"name": "parameters",
"type": "object",
"isBold": true,
"required": false,
"description": "The parameters the functions accept, described as a JSON Schema object.parameters defines a function with an empty parameter list."
},
{
"name": "strict",
"type": "boolean",
"isBold": true,
"required": false,
"defaultValue": "false",
"description": "Whether to enable strict schema adherence when generating the function call. If set to true, the model will follow the exact schema defined in the parameters field. Only a subset of JSON Schema is supported when strict is true."
}
]
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "Tool type. Currently, only function is supported."
}
]
},
{
"name": "Web search tool",
"type": "object",
"isBold": false,
"description": "A web search tool that can be used to generate a response.For details, please refer to Web Search.Note:Web Search plugin must be activated before use.", "children": [ { "name": "user_location", "type": "object", "isBold": true, "required": false, "children": [ { "name": "type", "type": "string", "isBold": true, "required": true, "description": "approximate" }, { "name": "country", "type": "string", "isBold": true, "required": false, "description": "country" }, { "name": "region", "type": "string", "isBold": true, "required": false, "description": "region" }, { "name": "city", "type": "string", "isBold": true, "required": false, "description": "city" }, { "name": "district", "type": "string", "isBold": true, "required": false, "description": "district" }, { "name": "longitude", "type": "long", "isBold": true, "required": false, "description": "longitude " }, { "name": "latitude", "type": "long", "isBold": true, "required": false, "description": "latitude" } ] }, { "name": "type", "type": "string", "isBold": true, "required": true, "description": "Tool type. Currently, only
web_search is supported."
},
{
"name": "force_search",
"type": "string",
"isBold": true,
"required": false,
"defaultValue": "false",
"description": "Whether to enable forced search. true for forced search, false for the model to decide whether search is needed."
},
{
"name": "max_keyword",
"type": "integer",
"isBold": true,
"required": false,
"defaultValue": "5",
"description": "Limit the maximum number of keywords that can be used in a single search.[1, 50]"
},
{
"name": "limit",
"type": "integer",
"isBold": true,
"required": false,
"defaultValue": "5",
"description": "Limit the maximum number of results returned by a single search operation.[1, 50]"
}
]
}
]
},
{
"name": "top_p",
"type": "number",
"isBold": true,
"required": false,
"defaultValue": "0.95",
"description": "The probability threshold for nucleus sampling, which controls the diversity of the text that the model generates. A higher top_p value results in more diverse text. A lower top_p value results in more deterministic text.temperature and top_p control the diversity of the generated text, we recommend that you set only one of them.[0.01, 1.0]"
}
]`} />
## Chat response object (non-streaming output)
length if the maximum number of tokens specified in the request was reached, tool_calls if the model called a tool, content_filter if content was omitted due to a flag from our content filters, repetition_truncation if the model detects repetition."
},
{
"name": "index",
"type": "integer",
"isBold": true,
"description": "The index of the choice in the list of choices."
},
{
"name": "message",
"type": "object",
"isBold": true,
"description": "A chat completion message generated by the model.",
"children": [
{
"name": "content",
"type": "string",
"isBold": true,
"description": "The contents of the message."
},
{
"name": "reasoning_content",
"type": "string",
"isBold": true,
"description": "The reasoning contents of the assistant message, before the final answer."
},
{
"name": "role",
"type": "string",
"isBold": true,
"description": "The role of the author of this message."
},
{
"name": "tool_calls",
"type": "array",
"isBold": true,
"description": "After a function call is initiated, the model returns the tool to be called and the parameters that are Required for the call. This parameter can contain one or more tool response objects.",
"children": [
{
"name": "Function tool call",
"type": "object",
"isBold": false,
"description": "A call to a function tool created by the model.",
"children": [
{
"name": "function",
"type": "object",
"isBold": true,
"description": "The function that the model called.",
"children": [
{
"name": "arguments",
"type": "string",
"isBold": true,
"description": "The arguments to call the function with, as generated by the model in JSON format. Note that the model does not always generate valid JSON, and may hallucinate parameters not defined by your function schema. Validate the arguments in your code before calling your function."
},
{
"name": "name",
"type": "string",
"isBold": true,
"description": "The name of the function to call."
}
]
},
{
"name": "id",
"type": "string",
"isBold": true,
"description": "The ID of the tool call."
},
{
"name": "type",
"type": "string",
"isBold": true,
"description": "The type of the tool. Currently, only function is supported."
}
]
}
]
},
{
"name": "annotations",
"type": "array",
"isBold": true,
"description": "After web search, the model returns annotations for all referenced URLs.",
"children": [
{
"name": "web_search tool call",
"type": "object",
"isBold": false,
"description": "A call to a web search tool created by the model.",
"children": [
{
"name": "logo_url",
"type": "string",
"isBold": true,
"description": "Logo url."
},
{
"name": "publish_time",
"type": "string",
"isBold": true,
"description": "Publish time."
},
{
"name": "site_name",
"type": "string",
"isBold": true,
"description": "Site name."
},
{
"name": "summary",
"type": "string",
"isBold": true,
"description": "Summary."
},
{
"name": "title",
"type": "string",
"isBold": true,
"description": "Title."
},
{
"name": "type",
"type": "string",
"isBold": true,
"description": "Type."
},
{
"name": "url",
"type": "string",
"isBold": true,
"description": "Url."
}
]
}
]
},
{
"name": "error_message",
"type": "string",
"isBold": true,
"description": "Error message of web search."
},
{
"name": "audio",
"type": "object",
"isBold": true,
"description": "If the audio output is requested, this object contains data about the audio response from the model.",
"children": [
{
"name": "id",
"type": "string",
"isBold": true,
"description": "Unique identifier for this audio response."
},
{
"name": "data",
"type": "string",
"isBold": true,
"description": "Base64 encoded audio bytes generated by the model, in the format specified in the request."
},
{
"name": "expires_at",
"type": [
"number",
"null"
],
"isBold": true,
"description": "The Unix timestamp (in seconds) for when this audio response expires. Currently always null."
},
{
"name": "transcript",
"type": [
"string",
"null"
],
"isBold": true,
"description": "Transcript of the audio generated by the model. Currently always null."
}
]
},
{
"name": "final_text_preview",
"type": "string",
"isBold": true,
"description": "The final audio broadcast text after intelligent optimization and polishing. This field is only returned when the request parameter optimize_text_preview is set to true."
}
]
}
]
},
{
"name": "created",
"type": "integer",
"isBold": true,
"description": "The Unix timestamp (in seconds) of when the chat completion was created."
},
{
"name": "id",
"type": "string",
"isBold": true,
"description": "A unique identifier for the chat completion."
},
{
"name": "model",
"type": "string",
"isBold": true,
"description": "The model to generate the completion."
},
{
"name": "object",
"type": "string",
"isBold": true,
"description": "The object type, which is always chat.completion."
},
{
"name": "usage",
"type": [
"object",
"null"
],
"isBold": true,
"description": "Usage statistics for the completion request.",
"children": [
{
"name": "completion_tokens",
"type": "integer",
"isBold": true,
"description": "Number of tokens in the generated completion."
},
{
"name": "prompt_tokens",
"type": "integer",
"isBold": true,
"description": "Number of tokens in the prompt."
},
{
"name": "total_tokens",
"type": "integer",
"isBold": true,
"description": "Total number of tokens used in the request (prompt + completion)."
},
{
"name": "completion_tokens_details",
"type": "object",
"isBold": true,
"description": "Breakdown of tokens used in a completion.",
"children": [
{
"name": "reasoning_tokens",
"type": "integer",
"isBold": true,
"description": "Tokens generated by the model for reasoning."
}
]
},
{
"name": "prompt_tokens_details",
"type": "object",
"isBold": true,
"description": "Breakdown of tokens used in the prompt.",
"children": [
{
"name": "cached_tokens",
"type": "integer",
"isBold": true,
"description": "Number of tokens served from cache."
},
{
"name": "audio_tokens",
"type": "integer",
"isBold": true,
"description": "Audio input tokens present in the prompt."
},
{
"name": "image_tokens",
"type": "integer",
"isBold": true,
"description": "Image input tokens present in the prompt."
},
{
"name": "video_tokens",
"type": "integer",
"isBold": true,
"description": "Video input tokens present in the prompt."
}
]
},
{
"name": "web_search_usage",
"type": "object",
"isBold": true,
"description": "Detailed usage of the web search API.",
"children": [
{
"name": "tool_usage",
"type": "integer",
"isBold": true,
"description": "Number of API calls in web search."
},
{
"name": "page_usage",
"type": "integer",
"isBold": true,
"description": "Number of web pages returned by the web search API."
}
]
}
]
}
]`} />
## Chat response chunk object (streaming output)
function is supported."
}
]
},
{
"name": "annotations",
"type": "array",
"isBold": true,
"description": "After web search, the model returns annotations for all referenced URLs.",
"children": [
{
"name": "web_search tool call",
"type": "object",
"isBold": false,
"description": "A call to a web search tool created by the model.",
"children": [
{
"name": "logo_url",
"type": "string",
"isBold": true,
"description": "Logo url."
},
{
"name": "publish_time",
"type": "string",
"isBold": true,
"description": "Publish time."
},
{
"name": "site_name",
"type": "string",
"isBold": true,
"description": "Site name."
},
{
"name": "summary",
"type": "string",
"isBold": true,
"description": "Summary."
},
{
"name": "title",
"type": "string",
"isBold": true,
"description": "Title."
},
{
"name": "type",
"type": "string",
"isBold": true,
"description": "Type."
},
{
"name": "url",
"type": "string",
"isBold": true,
"description": "Url."
}
]
}
]
},
{
"name": "error_message",
"type": "string",
"isBold": true,
"description": "Error message of web search."
},
{
"name": "audio",
"type": [
"object",
"null"
],
"isBold": true,
"description": "If the audio output modality is requested, this object contains data about the audio response from the model.",
"children": [
{
"name": "id",
"type": "string",
"isBold": true,
"description": "Unique identifier for this audio response."
},
{
"name": "data",
"type": "string",
"isBold": true,
"description": "Base64 encoded audio bytes generated by the model, in the format specified in the request."
},
{
"name": "expires_at",
"type": [
"number",
"null"
],
"isBold": true,
"description": "The Unix timestamp (in seconds) for when this audio response expires. Currently always null."
},
{
"name": "transcript",
"type": [
"string",
"null"
],
"isBold": true,
"description": "Transcript of the audio generated by the model. Currently always null."
}
]
},
{
"name": "final_text_preview",
"type": "string",
"isBold": true,
"description": "The final audio broadcast text after intelligent optimization and polishing. This field is only returned when the request parameter optimize_text_preview is set to true."
}
]
},
{
"name": "finish_reason",
"type": [
"string",
"null"
],
"isBold": true,
"description": "The reason the model stopped generating tokens. This will be stop if the model hit a natural stop point or a provided stop sequence, length if the maximum number of tokens specified in the request was reached, tool_calls if the model called a tool, content_filter if content was omitted due to a flag from our content filters, repetition_truncation if the model detects repetition."
},
{
"name": "index",
"type": "integer",
"isBold": true,
"description": "The index of the choice in the list of choices."
}
]
},
{
"name": "created",
"type": "integer",
"isBold": true,
"description": "The Unix timestamp (in seconds) of when the chat completion was created. Each chunk has the same timestamp."
},
{
"name": "id",
"type": "string",
"isBold": true,
"description": "A unique identifier for the chat completion. Each chunk has the same ID."
},
{
"name": "model",
"type": "string",
"isBold": true,
"description": "The model to generate the completion."
},
{
"name": "object",
"type": "string",
"isBold": true,
"description": "The object type, which is always chat.completion.chunk."
},
{
"name": "usage",
"type": [
"object",
"null"
],
"isBold": true,
"description": "Usage statistics for the completion request.",
"children": [
{
"name": "completion_tokens",
"type": "integer",
"isBold": true,
"description": "Number of tokens in the generated completion."
},
{
"name": "prompt_tokens",
"type": "integer",
"isBold": true,
"description": "Number of tokens in the prompt."
},
{
"name": "total_tokens",
"type": "integer",
"isBold": true,
"description": "Total number of tokens used in the request (prompt + completion)."
},
{
"name": "completion_tokens_details",
"type": "object",
"isBold": true,
"description": "Breakdown of tokens used in a completion.",
"children": [
{
"name": "reasoning_tokens",
"type": "integer",
"isBold": true,
"description": "Tokens generated by the model for reasoning."
}
]
},
{
"name": "prompt_tokens_details",
"type": "object",
"isBold": true,
"description": "Breakdown of tokens used in the prompt.",
"children": [
{
"name": "cached_tokens",
"type": "integer",
"isBold": true,
"description": "Number of tokens served from cache."
},
{
"name": "audio_tokens",
"type": "integer",
"isBold": true,
"description": "Audio input tokens present in the prompt."
},
{
"name": "image_tokens",
"type": "integer",
"isBold": true,
"description": "Image input tokens present in the prompt."
},
{
"name": "video_tokens",
"type": "integer",
"isBold": true,
"description": "Video input tokens present in the prompt."
}
]
},
{
"name": "web_search_usage",
"type": "object",
"isBold": true,
"description": "Detailed usage of the web search API.",
"children": [
{
"name": "tool_usage",
"type": "integer",
"isBold": true,
"description": "Number of API calls in web search."
},
{
"name": "page_usage",
"type": "integer",
"isBold": true,
"description": "Number of web pages returned by the web search API."
}
]
}
]
}
]`} />
--- DOCUMENT: Anthropic API ---
URL: https://platform.xiaomimimo.com/static/docs/api/chat/anthropic-api.md
# Anthropic API Compatibility
## Request Address
```bash
https://api.xiaomimimo.com/anthropic/v1/messages
```
## Request Headers
The API supports the following two authentication methods. Please choose one and add it to the request headers:
1. Method 1: `api-key` field authentication, format:
```json
api-key: $MIMO_API_KEY
Content-Type: application/json
```
1. Method 2: `Authorization: Bearer` authentication, format:
```json
Authorization: Bearer $MIMO_API_KEY
Content-Type: application/json
```
## Request Body
content.content may be either a single string or an array of content blocks, where each block has a specific type. Using a string for content is shorthand for an array of one content block of type text.",
"children": [
{
"name": "role",
"type": "string",
"isBold": true,
"required": true,
"description": "Role of the message.user, assistant"
},
{
"name": "content",
"type": [
"string",
"array"
],
"isBold": true,
"required": true,
"children": [
{
"name": "Text content",
"type": "string",
"isBold": false,
"description": "The text contents of the message."
},
{
"name": "Array of content parts",
"type": "array",
"isBold": false,
"description": "An array of content parts with a defined type. Such text, image, tool use, tool result, and thinking.Only the", "children": [ { "name": "Text", "type": "object", "isBold": false, "children": [ { "name": "text", "type": "string", "isBold": true, "required": true, "description": "The content of the text block.mimo-v2.5andmimo-v2-omnimodels support image input.
1"
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content.text"
}
]
},
{
"name": "Image",
"type": "object",
"isBold": false,
"children": [
{
"name": "source",
"type": "object",
"isBold": true,
"required": true,
"description": "Image data is provided via URL or Base64.",
"children": [
{
"name": "Base64ImageSource",
"type": "object",
"isBold": false,
"children": [
{
"name": "data",
"type": "string",
"isBold": true,
"required": true,
"description": "Base64 encoded image data."
},
{
"name": "media_type",
"type": "string",
"isBold": true,
"required": true,
"description": "Media type.image/jpeg, image/png, image/gif, image/webp, image/bmp"
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "Image source type.base64"
}
]
},
{
"name": "URLImageSource",
"type": "object",
"isBold": false,
"children": [
{
"name": "url",
"type": "string",
"isBold": true,
"required": true,
"description": "A URL of the image."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "Image source type.url"
}
]
}
]
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content.image"
}
]
},
{
"name": "Tool use",
"type": "object",
"isBold": false,
"children": [
{
"name": "id",
"type": "string",
"isBold": true,
"required": true,
"description": "The unique identifier for tool use."
},
{
"name": "input",
"type": "object",
"isBold": true,
"required": true,
"description": "The parameter object passed when using the tool."
},
{
"name": "name",
"type": "string",
"isBold": true,
"required": true,
"description": "Tool name."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content.tool_use"
}
]
},
{
"name": "Tool result",
"type": "object",
"isBold": false,
"children": [
{
"name": "tool_use_id",
"type": "string",
"isBold": true,
"required": true,
"description": "The tool_use ID corresponding to this result."
},
{
"name": "content",
"type": [
"string",
"array"
],
"isBold": true,
"description": "The result returned after the tool is executed.",
"children": [
{
"name": "Text content",
"type": "string",
"isBold": false,
"description": "The text contents of the message."
},
{
"name": "Array of content parts",
"type": "array",
"isBold": false,
"description": "An array of content parts with a defined type. Such text and image.",
"children": [
{
"name": "Text",
"type": "object",
"isBold": false,
"children": [
{
"name": "text",
"type": "string",
"isBold": true,
"required": true,
"description": "The content of the text block."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content.text"
}
]
},
{
"name": "Image",
"type": "object",
"isBold": false,
"children": [
{
"name": "source",
"type": "object",
"isBold": true,
"required": true,
"description": "Image data is provided via URL or Base64.",
"children": [
{
"name": "Base64ImageSource",
"type": "object",
"isBold": false,
"children": [
{
"name": "data",
"type": "string",
"isBold": true,
"required": true,
"description": "Base64 encoded image data."
},
{
"name": "media_type",
"type": "string",
"isBold": true,
"required": true,
"description": "Media type.image/jpeg, image/png, image/gif, image/webp, image/bmp"
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "Image source type.base64"
}
]
},
{
"name": "URLImageSource",
"type": "object",
"isBold": false,
"children": [
{
"name": "url",
"type": "string",
"isBold": true,
"required": true,
"description": "A URL of the image."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "Image source type.url"
}
]
}
]
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content.image"
}
]
}
]
}
]
},
{
"name": "is_error",
"type": "boolean",
"isBold": true
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content.tool_result"
}
]
},
{
"name": "Thinking",
"type": "object",
"isBold": false,
"children": [
{
"name": "signature",
"type": "string",
"isBold": true,
"description": "The signature of the thinking block."
},
{
"name": "thinking",
"type": "string",
"isBold": true,
"required": true,
"description": "Thinking content."
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content.thinking"
}
]
}
]
}
]
}
]
},
{
"name": "model",
"type": "string",
"isBold": true,
"required": true,
"description": "The model that will complete your prompt.mimo-v2.5-pro, mimo-v2.5, mimo-v2-pro, mimo-v2-omni, mimo-v2-flash"
},
{
"name": "max_tokens",
"type": "integer",
"isBold": true,
"required": false,
"description": "The maximum number of tokens to generate before stopping.mimo-v2-flash: default 65536mimo-v2.5-pro, mimo-v2-pro: default 131072mimo-v2.5, mimo-v2-omni: default 32768[1, 131072]"
},
{
"name": "stop_sequences",
"type": "array",
"isBold": true,
"required": false,
"description": "Custom text sequences that will cause the model to stop generating.stop_reason of end_turn.stop_sequences parameter."
},
{
"name": "stream",
"type": "boolean",
"isBold": true,
"required": false,
"defaultValue": "false",
"description": "Whether to incrementally stream the response using server-sent events."
},
{
"name": "system",
"type": [
"string",
"array"
],
"isBold": true,
"required": false,
"description": "A system prompt is a way of providing context and instructions to model, such as specifying a particular goal or role.",
"children": [
{
"name": "Text content",
"type": "string",
"isBold": false,
"description": "The content of the system prompt."
},
{
"name": "Array of content parts",
"type": "array",
"isBold": false,
"children": [
{
"name": "text",
"type": "string",
"isBold": true,
"required": true,
"description": "The text content.1"
},
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of the content.text"
}
]
}
]
},
{
"name": "temperature",
"type": "number",
"isBold": true,
"required": false,
"description": "Sampling temperature controls the diversity of the text generated by the model.In thinking mode, themimo-v2.5-proandmimo-v2.5models do not support customizing thetemperatureparameter. Even if this parameter is passed in, it will be forcibly overridden and take effect with the model's recommended default value of1.0.
mimo-v2-flash: default 0.3mimo-v2.5-pro, mimo-v2.5, mimo-v2-pro, mimo-v2-omni: default 1.0[0, 1.5]"
},
{
"name": "thinking",
"type": "object",
"isBold": true,
"required": false,
"description": "Configuration for enabling model's extended thinking.Note: During the multi-turn tool calls process in thinking mode, the model returns athinkingcontent block alongsidetool_usecontent block. To continue the conversation, it is recommended to keep all previousthinkingcontent block in themessagesarray for each subsequent request to achieve the best performance.
In thinking mode, the", "children": [ { "name": "type", "type": "string", "isBold": true, "required": true, "description": "mimo-v2.5-proandmimo-v2.5models do not support customizing thetemperatureparameter. Even if this parameter is passed in, it will be forcibly overridden and take effect with the model's recommended default value of1.0.
mimo-v2-flash: default disabledmimo-v2.5-pro, mimo-v2.5, mimo-v2-pro, mimo-v2-omni: default enabledenabled, disabled"
}
]
},
{
"name": "tool_choice",
"type": "object",
"isBold": true,
"required": false,
"description": "How the model should use the provided tools.",
"children": [
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "auto means the model will automatically decide whether to use tools.Note: When a value other thanAvailable options:autois passed totype, the backend will remove this field by default, and the model response behavior will still be equivalent to theautomode (this logic is subject to future adjustments).
auto"
},
{
"name": "disable_parallel_tool_use",
"type": "boolean",
"isBold": true,
"defaultValue": "false",
"description": "Whether to disable parallel tool use.true:auto, the model will output at most one tool use.tools in your API request, the model may return tool_use content blocks that represent the model's use of those tools. You can then run those tools using the tool input generated by the model and then optionally return results back to the model using tool_result content blocks.Note: During the multi-turn tool calls process in thinking mode, the model returns aEach tool definition includes:thinkingcontent block alongsidetool_usecontent block. To continue the conversation, it is recommended to keep all previousthinkingcontent block in themessagesarray for each subsequent request to achieve the best performance.
name: Name of the tool.description: Optional, but strongly-recommended description of the tool.input_schema: JSON schema for the tool input shape that the model will produce in tool_use output content blocks.tool_use blocks."
},
{
"name": "description",
"type": "string",
"isBold": true,
"description": "Description of what this tool does.custom"
},
{
"name": "input_schema",
"type": "object",
"isBold": true,
"required": true,
"description": "JSON schema for the tool input shape that the model will produce in tool_use output content blocks.",
"children": [
{
"name": "type",
"type": "string",
"isBold": true,
"required": true,
"description": "The type of input_schema, only object is supported.object"
},
{
"name": "properties",
"type": [
"object",
"null"
],
"isBold": true,
"description": "The properties of the tool input."
},
{
"name": "required",
"type": [
"array",
"null"
],
"isBold": true,
"description": "The list of properties that must be included in the tool input."
}
]
}
]
},
{
"name": "top_p",
"type": "number",
"isBold": true,
"required": false,
"defaultValue": "0.95",
"description": "Use nucleus sampling.top_p. You should either alter temperature or top_p, but not both.temperature.[0.01, 1.0]"
}
]`} />
## Non-streaming Response
assistant."
},
{
"name": "content",
"type": "array",
"isBold": true,
"description": "Content generated by the model.",
"children": [
{
"name": "Text",
"type": "object",
"isBold": false,
"children": [
{
"name": "text",
"type": "string",
"isBold": true,
"description": "The content of the text."
},
{
"name": "type",
"type": "string",
"isBold": true,
"description": "The type of the content.text"
}
]
},
{
"name": "Thinking",
"type": "object",
"isBold": false,
"children": [
{
"name": "signature",
"type": "string",
"isBold": true,
"description": "The signature of the thinking block."
},
{
"name": "thinking",
"type": "string",
"isBold": true,
"description": "Thinking content."
},
{
"name": "type",
"type": "string",
"isBold": true,
"description": "The type of the content.thinking"
}
]
},
{
"name": "Tool use",
"type": "object",
"isBold": false,
"children": [
{
"name": "id",
"type": "string",
"isBold": true,
"description": "The unique identifier for tool use."
},
{
"name": "input",
"type": "object",
"isBold": true,
"description": "The parameter object passed when using the tool."
},
{
"name": "name",
"type": "string",
"isBold": true,
"description": "Tool name."
},
{
"name": "type",
"type": "string",
"isBold": true,
"description": "The type of the content.tool_use"
}
]
}
]
},
{
"name": "model",
"type": "string",
"isBold": true,
"description": "The model that handled the request."
},
{
"name": "stop_reason",
"type": "string",
"isBold": true,
"description": "The reason the message finished.end_turn: the model reached a natural stopping point.max_tokens: we exceeded the requested max_tokens or the model's maximum.tool_use: the model invoked one or more tools.content_filter: the content was omitted due to a flag from our content filters.repetition_truncation: the model detects repetition.end_turn, max_tokens, tool_use, content_filter, repetition_truncation"
},
{
"name": "usage",
"type": "object",
"isBold": true,
"description": "Billing and rate-limit usage.",
"children": [
{
"name": "input_tokens",
"type": "integer",
"isBold": true,
"description": "The number of input tokens which were used."
},
{
"name": "output_tokens",
"type": "integer",
"isBold": true,
"description": "The number of output tokens which were used."
},
{
"name": "cache_read_input_tokens",
"type": [
"integer",
"null"
],
"isBold": true,
"description": "The number of input tokens read from the cache."
}
]
}
]`} />
## Streaming Response
message_start, content_block_start, content_block_delta, content_block_stop, message_delta, message_stop"
},
{
"name": "type",
"type": "string",
"isBold": true,
"description": "Each server-sent event includes a named event type and associated JSON data.message_start, content_block_start, content_block_delta, content_block_stop, message_delta, message_stop"
},
{
"name": "message",
"type": "object",
"isBold": true,
"description": "Response message.",
"children": [
{
"name": "id",
"type": "string",
"isBold": true,
"description": "The message ID."
},
{
"name": "type",
"type": "string",
"isBold": true,
"description": "Available options: message"
},
{
"name": "role",
"type": "string",
"isBold": true,
"description": "Available options: assistant"
},
{
"name": "model",
"type": "string",
"isBold": true,
"description": "The model name."
},
{
"name": "content",
"type": "array",
"isBold": true,
"description": "The array of content blocks in the message."
},
{
"name": "stop_reason",
"type": [
"string",
"null"
],
"isBold": true,
"description": "The reason the message finished."
}
]
},
{
"name": "index",
"type": "integer",
"isBold": true,
"description": "The position of the content block within the message.。"
},
{
"name": "content_block",
"type": "object",
"isBold": true,
"description": "The content block that is starting.",
"children": [
{
"name": "Text",
"type": "object",
"isBold": false,
"children": [
{
"name": "type",
"type": "string",
"isBold": true,
"description": "The header for a text content block; actual text arrives via subsequent delta events.text"
},
{
"name": "text",
"type": "string",
"isBold": true,
"description": "Often an empty string at start; text is appended via content_block_delta events of type text_delta."
}
]
},
{
"name": "Thinking",
"type": "object",
"isBold": false,
"children": [
{
"name": "type",
"type": "string",
"isBold": true,
"description": "The header for a thinking content block; actual thinking content arrives via subsequent delta events.thinking"
},
{
"name": "thinking",
"type": "string",
"isBold": true,
"description": "Often an empty string at start; thinking content is appended via content_block_delta events of type thinking_delta."
}
]
},
{
"name": "Tool use",
"type": "object",
"isBold": false,
"children": [
{
"name": "type",
"type": "string",
"isBold": true,
"description": "Available options: tool_use"
},
{
"name": "id",
"type": "string",
"isBold": true,
"description": "The unique identifier for tool use."
},
{
"name": "name",
"type": "string",
"isBold": true,
"description": "Tool name."
},
{
"name": "input",
"type": "object",
"isBold": true,
"description": "The parameter object passed when using the tool."
}
]
}
]
},
{
"name": "delta",
"type": "object",
"isBold": true,
"description": "Actual response content.",
"children": [
{
"name": "Content block delta",
"type": "object",
"isBold": false,
"description": "Incremental data for a content block.",
"children": [
{
"name": "type",
"type": "string",
"isBold": true,
"description": "Available options: text_delta, thinking_delta, input_json_delta"
},
{
"name": "text",
"type": "string",
"isBold": true,
"description": "The text part of the incremental data."
},
{
"name": "thinking",
"type": "string",
"isBold": true,
"description": "The thinking part of the incremental data."
},
{
"name": "partial_json",
"type": "string",
"isBold": true,
"description": "A JSON fragment string. Clients should concatenate fragments in arrival order to form the complete input JSON, then parse."
}
]
},
{
"name": "Message delta",
"type": "object",
"isBold": false,
"description": "Message-level stop metadata updates.",
"children": [
{
"name": "stop_reason",
"type": [
"string",
"null"
],
"isBold": true,
"description": "The reason the message finished.end_turn, max_tokens, tool_use, content_filter, repetition_truncation"
}
]
}
]
},
{
"name": "usage",
"type": [
"object",
"null"
],
"isBold": true,
"description": "Billing and rate-limit usage.",
"children": [
{
"name": "input_tokens",
"type": "integer",
"isBold": true,
"description": "The number of input tokens which were used."
},
{
"name": "output_tokens",
"type": "integer",
"isBold": true,
"description": "The number of output tokens which were used."
},
{
"name": "cache_read_input_tokens",
"type": [
"integer",
"null"
],
"isBold": true,
"description": "The number of input tokens read from the cache."
}
]
}
]`} />
--- DOCUMENT: Subscription Instructions ---
URL: https://platform.xiaomimimo.com/static/docs/tokenplan/subscription.md
# Subscription Instructions
**Token Plan** is a dedicated subscription plan launched for AI programming scenarios. You can use the cost-effective subscription resource package to call the MiMo flagship large model in various mainstream AI development tools.
## Core Advantages
- **Covers flagship models** - Supports MiMo-V2.5-Pro, MiMo-V2.5, MiMo-V2.5-TTS-VoiceClone, MiMo-V2.5-TTS-VoiceDesign, MiMo-V2.5-TTS, including a total of 8 models in the V2 series. It adopts a Token conversion mechanism, with transparent and controllable quotas.
- **Elastic Subscription Plan** — Four-tier Gradient Package, meeting the needs from individual development to enterprise-level development
- **Multi-ecosystem Out Of The Box** — Compatible with mainstream development toolchains such as OpenCode, OpenClaw, and Claude Code
## Usage Quota
#### Monthly Package
| **Lite** | **Standard** | **Pro** | **Max** | |
|---|---|---|---|---|
| **Pricing** | **$6/month, ¥39/month** | **$16/month, ¥99/month** | **$50/month, ¥329/month** | **$100/month, ¥659/month** |
| **Monthly Fixed Credit Limit** | **60,000,000 (60M)Credits** | **200,000,000 (200M)Credits** | **700,000,000 (700M)Credits** | **1,600,000,000 (1600M)Credits** |
| **Lite** | **Standard** | **Pro** | **Max** | |
|---|---|---|---|---|
| **Pricing** | **$63.36/year,¥411.84/year** | **$168.96/year,¥1045.44/year** | **$528.00/year,¥3474.24/year** | **$1056.00/year,¥6959.04/year** |
| **Yearly Fixed Credit Limit** | **720,000,000 (720M)Credits** | **2,400,000,000 (2400M)Credits** | **8,400,000,000 (8400M)Credits** | **19,200,000,000 (19200M)Credits** |
| **Lite** | **Standard** | **Pro** | **Max** | |
|---|---|---|---|---|
| **Applicable Scenarios** | Suitable for first-time lobster-tasting users Using MiMo-V2.5/MiMo-V2-Omni as a benchmark, it can execute approximately **120 rounds of medium to complex tasks** |
Suitable for work enthusiasts who often use AI to improve their efficiency Using MiMo-V2.5/MiMo-V2-Omni as a benchmark, it can execute approximately **400 rounds of medium to complex tasks** |
Suitable for developers and professional efficiency enthusiasts who use AI frequently every day Using MiMo-V2.5/MiMo-V2-Omni as a baseline, approximately **1400 rounds of medium to complex tasks can be executed** |
Suitable for high-intensity, hardcore users who use AI as a core productivity tool Using MiMo-V2.5/MiMo-V2-Omni as a baseline, it can execute approximately **3200 rounds of medium to complex tasks** |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage | Description | Acquisition Method (BASE_URL and API Key below are both examples) |
|---|---|---|
| Pay-as-you-go API call | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [ Subscription Management ](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Usage Method | Description | Acquisition Method (BASE_URL and API Key below are examples) |
|---|---|---|
| Pay-as-you-go MiMo API | Charged based on actual usage, suitable for light use |
Go to [API Keys](https://platform.xiaomimimo.com/#/console/api-keys) to create an API Key |
| Token Plan | Fixed subscription fee, with limited calls based on the package |
After successful subscription, go to [Subscription](https://platform.xiaomimimo.com/#/console/plan-manage) to obtain the exclusive Base URL and API Key |
| Model Name | Model ID | Function | Voice | Precautions |
|---|---|---|---|---|
| MiMo-V2.5-TTS | `mimo-v2.5-tts` | Use built-in high-quality voices for speech synthesis | Use the high-quality voices from the built-in voices list | Supports singing mode, does not support voice design and voice cloning |
| MiMo-V2.5-TTS-VoiceDesign | `mimo-v2.5-tts-voicedesign` | Customize voice through text description | Automatically generate voices from text descriptions, without requiring presets or audio samples | Does not support singing mode, built-in voices, or voice cloning |
| MiMo-V2.5-TTS-VoiceClone | `mimo-v2.5-tts-voiceclone` | Replicate any voice from audio samples | Precisely replicate voices from audio samples to enable speech synthesis of any voice | Does not support singing mode, built-in voices, or voice design |
| **Style Type** | **Style Example** |
|---|---|
| Basic Emotions | *Happy / Sad / Angry / Fearful / Amazed / Excited / Wronged / Calm / Indifferent* |
| Complex Emotions | *Melancholy / Relieved / Helpless / Guilty / Relieved / Jealous / Tired / Apprehensive / Emotional* |
| Overall tone | *Gentle / Cold / Lively / Serious / Lazy / Playful / Deep / Capable / Sharp* |
| Timbre Positioning | *Magnetic / Mellow / Clear / Ethereal / Innocent / Old / Sweet / Hoarse / Elegant* |
| Character Tone | *Clamp voice / Big Sister voice / Shota voice / Uncle voice / Taiwanese accent* |
| Dialect | *Northeast dialect / Sichuan dialect / Henan dialect / Cantonese* |
| Role-playing | *Sun Wukong / Lin Daiyu* |
| Singing | *singing* |
| **Style Type** | **Style Example** |
|---|---|
| Speech Rate and Rhythm | *Inhale / Take a deep breath / Sigh / Let out a long sigh / Pant / Hold one's breath* |
| Emotional State | *nervous / scared / excited / tired / wronged / coquettish / guilty / shocked / impatient* |
| Speech Features | *Trembling / Voice trembling / Pitch change / Cracked voice / Nasal voice / Breathiness / Hoarseness* |
| Laughing and crying tone | *Smile / Chuckle / Laugh out loud / Sneer / Sob / Whimper / Choke / Wail* |
| **Voice** **Name** | **Voice ID** | Language | Gender |
|---|---|---|---|
| MiMo-默认 | mimo_default | It varies depending on the deployed cluster. The default for the China cluster is `冰糖`, and the default for other clusters is `Mia` | |
| 冰糖 | 冰糖 | Chinese | Female |
| 茉莉 | 茉莉 | Chinese | Female |
| 苏打 | 苏打 | Chinese | Male |
| 白桦 | 白桦 | Chinese | Male |
| Mia | Mia | English | Female |
| Chloe | Chloe | English | Female |
| Milo | Milo | English | Male |
| Dean | Dean | English | Male |
| Dimension | Example |
|---|---|
| Gender and Age | "young woman in her mid-20s", "middle-aged man in his 50s" |
| Voice / Texture | "deep and gravelly", "silky, mellow, and magnetic" |
| Mood / Tone | "warm and confident", "gentle but with a hint of weariness" |
| Speech speed / Rhythm | "slow and deliberate", "speaking at an extremely fast pace, like a machine gun." |
| Protocol | **Affected Agent Products** |
|---|---|
| OpenAI Compatibility Protocol | TRAE, Cursor, Roo Code, Codex, GitHub Copilot CLI, Zed, AutoGen, Goose |
| Anthropic Compatibility Protocol | TRAE, GitHub Copilot CLI, AutoGen, Goose, OpenClaw, OpenCode, Kilo Code |
| Data Controller | the natural or public or private legal person who alone or jointly with others determines the purpose, content and use of the Personal Data. |
|---|---|
| Data Processor | an entity that processes Personal Data on behalf of a Data Controller. |
| Personal Data | any numerical, alphabetical, graphic, photographic, acoustic or any other type of information relating to identified or identifiable natural persons shared between the Parties pursuant to the Agreement and this Addendum. |
| Transfer | the access by, transfer or delivery to, or disclosure of Personal Data to a person, entity or system located in a country or jurisdiction other than the country or jurisdiction from where the Personal Data originated. |
| Data Protection Legislation | any laws and regulations relating to the processing of Personal Data and privacy of the territory and, if applicable, the guidance and codes of practice issued by the relevant data protection or Supervisory Authority. |
| Data Breach | a breach of security leading to the accidental or unlawful destruction, loss, alteration, unauthorized disclosure of, or access to the Personal Data. |