MiMo-V2-Flash: 高效推理、代码与 Agent 基座模型
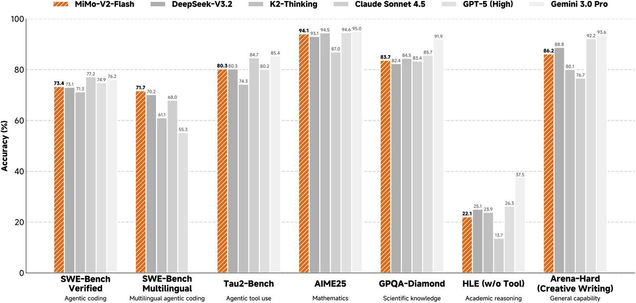
mimo-v2-flash 正式开源!这是一个专为极致推理效率自研的总参数 309B(激活 15B)的 MoE 模型,通过 Hybrid 注意力架构创新及多层 MTP 推理加速,在多个 Agent 测评基准上保持进入全球开源模型 Top 2;代码能力超过所有开源模型,比肩标杆闭源模型 Claude 4.5 Sonnet,但推理成本仅为其 2.5%,生成速度提升 2 倍,成功将大模型推理效率推向极致。
秉持开放精神,模型权重和推理代码均采用 MIT 协议全面开源。API 限时免费。
推理成本与速度的极致优化
mimo-v2-flash 的 API 定价为: 输入 $0.1/M tokens,输出 $0.3/M tokens。
下图横轴为全球顶尖模型速度和成本的对比图,mimo-v2-flash 实现了最低成本、最高速度。

面向高效推理的结构创新
结构要点如下:
- 混合注意力:采用 1:5 的 Global Attention 与 Sliding Window Attention (SWA) 混合结构,128 窗口大小,原生 32K 外扩 256K 训练。经前期大量实证发现,SWA 简单、高效、易用,展现了比主流 Linear Attention 综合更佳的通用、长文和推理能力,并提供了固定大小的 KV Cache 从而极易适配现有训练和推理 Infra 框架。
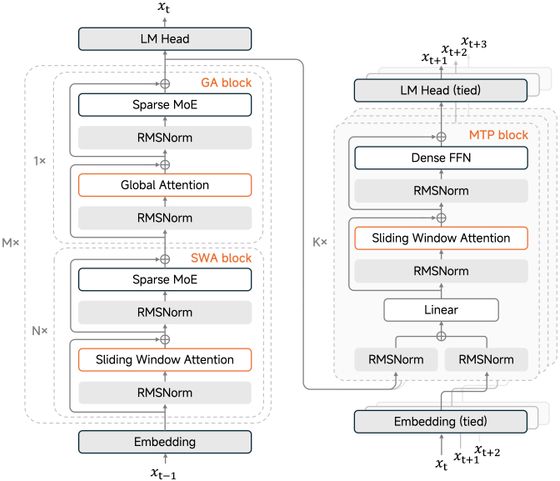
- MTP推理加速:通过引入 MTP (Multi-Token Prediction) 训练提升基座能力的同时,并在推理阶段通过并行验证 MTP Token,打破了传统 Decoding 在大 Batch 下的显存带宽瓶颈,实测在 3 层 MTP 情况下可实现 2.5~3.7 的实际加速比。
相关链接
更新时间 2026 年 05 月 28 日