Xiaomi MiMo-V2-Omni 发布:看得清,听得懂,能动手的全模态 Agent 基座
今天,我们发布小米面向 Agent 时代的全模态基座模型 Xiaomi mimo-v2-omni。
mimo-v2-omni 专为现实世界中复杂的多模态交互与执行场景而生。我们从底层构建了融合文本、视觉、语音的全模态基座,并以统一架构将“感知”与“行动”深度绑定。这不仅打破了传统模型“重理解、轻执行”的局限,更让模型原生具备了多模态感知、工具调用、函数执行及 GUI 操作能力。mimo-v2-omni 可无缝接入各大智能体框架,实现了从理解到操控的跨越,大幅降低了全模态 Agent 的落地门槛。
感知能力:图像、视频、音频,全面对标前沿
行动的前提是准确的感知。我们在所有感知模态上对比了 mimo-v2-omni 与国际领先模型,验证作为智能体的感知能力基础是否牢固。
视觉理解方面,mimo-v2-omni 展现出强大的多学科视觉推理与复杂图表分析能力,超越 Claude Opus 4.6,逼近 Gemini 3 等顶尖闭源模型水平。
音频理解方面,支持从环境声分类、多说话人分离、音频-视觉联合推理,到超过 10 小时连续长音频的深度理解。综合表现超越 Gemini 3 Pro,是当前最强的音频理解基座模型之一。
视频理解方面,支持原生音视频联合输入,实现真正的多模态视频理解。通过创新的视频预训练,模型具备强大的情境感知与未来推理能力。
而当多种模态同时输入时,统一架构的优势进一步放大:跨模态信号相互增强,而非相互竞争。
智能体能力:从理解到完成任务
感知是基础,行动是目标。
一个真正的智能体模型,能够跨越多个模态观察复杂环境、制定计划并执行、在出错时自主恢复,最终端到端地交付结果。
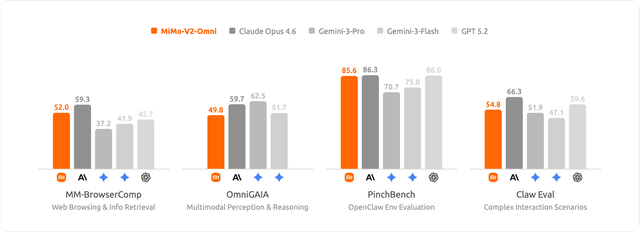
全模态智能体任务
在与真实数字环境交互的评测基准上,mimo-v2-omni 表现优异,比肩 Gemini 3 Pro。前沿的感知能力与原生训练的行动能力形成了复合优势:感知越准确,行动越有效。
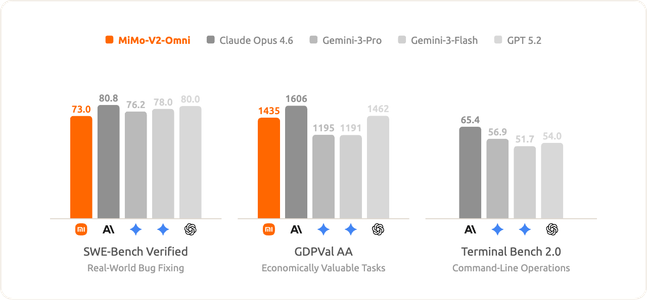
与此同时,mimo-v2-omni 在纯文本智能体任务上也保持了高度的竞争力。
能力展示
💻 Browser Use场景
Browser Use 是衡量模型 Agentic 能力的试金石:真实世界交互、网页环境动态变化、交互方式异构、且存在主动的对抗机制。感知、决策、行动的闭环在开放环境中持续运转直至任务完成——同样的能力迁移到智能终端、机器人等场景,就是通用智能体的雏形。
-
替你逛街砍价下单 我们测试了一个端到端购物任务。模型操控浏览器,先在小红书浏览十余篇帖子完成信息搜集与购买建议,再跨平台切到京东多店比价,接着转接人工客服用自然语言砍价,与客服实时交互,最终完成加购下单。模型自主应对了非标准 DOM 结构、多页签上下文管理、以及平台反自动化检测后的流程恢复。
-
TikTok 视频创作发布 我们测试了一个端到端视频发布任务。模型自主设计四组画面并现场合成全部音效,零外部素材依赖;渲染时遇到中文字体报错,自动修复后继续执行;再操控浏览器打开 TikTok 上传页面,分析非标准输入控件完成文案填写,点击发布后继续点赞、评论,回查确认审核通过、视频公开上线。
🗒️ 智能办公场景
通过自然对话,mimo-v2-omni 能够直接生成高质量的 Word、结构化 Excel、排版规范的 PDF 与完整的 PPT。这些生成的文档不再是需要大幅修改的草稿,而是贴合实际需求的高质量“准终稿”。
-
2026高考志愿智能填报
我们测试了高考志愿填报任务。模型可以自主发起网络搜索,获取原始信息,调用 skill 处理文件,并输出一份包含详细志愿建议和分级的 Excel 表格文件。
开放 API
mimo-v2-omni 模型现已正式开放 API 服务,支持 256K 上下文长度:
-
输入 $0.4 / 百万 tokens;
-
输出 $2 / 百万 tokens。
访问 https://platform.xiaomimimo.com 即刻接入API。