MiMo-V2-Flash: High-Efficiency Inference, Code & Agent Foundation Model
Xiaomi mimo-v2-flash is officially open-sourced today!!! It is a MoE (Mixture of Experts) model designed for extreme inference efficiency, with 309B total and 15B activated parameters.
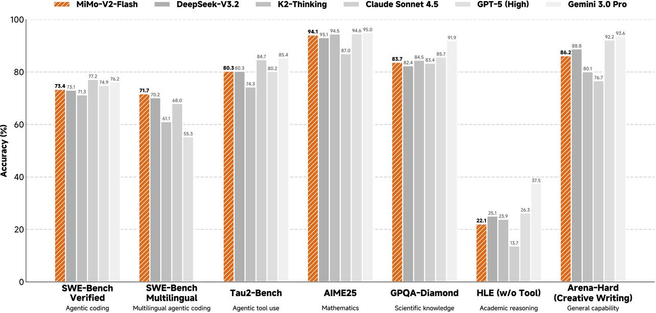
With an innovative hybrid attention and multi-layer MTP (Multi-Token Prediction) architecture, the model ranks top 2 among all open-source models across multiple agent evaluation benchmarks. Besides, its coding capability surpasses all open-source models and is comparable with Claude 4.5 Sonnet, while its inference cost is only 2.5% of Claude’s and its generation speed is doubled — pushing inference efficiency to the limit.
To foster open-source engagement, both the model weights and inference code are fully open-sourced under the MIT license.
The API is available free of charge for a limited time.
Extreme Optimization of Cost and Speed
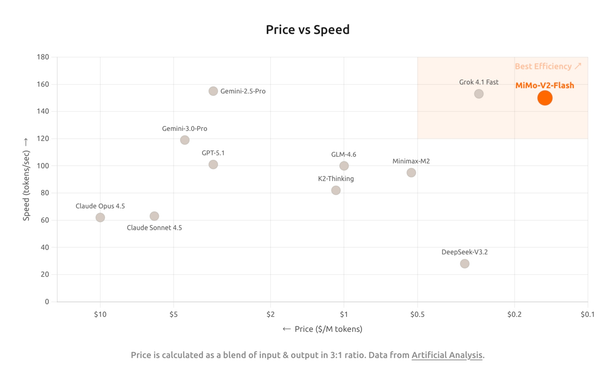
The API pricing for mimo-v2-flash is $0.1 per million input tokens and $0.3 per million output tokens.
In the chart below, the horizontal axis compares speed and cost across leading models——mimo-v2-flash achieves both the lowest cost and the highest speed.
Architectural innovations designed for high-efficiency inference
Key architectural designs:
- Hybrid Attention: We adopt a hybrid attention mechanism combining Global Attention and Sliding Window Attention (SWA) at a 1:5 ratio, where the window size of SWA is 128. During pre-training, we train the model with a context length of 32k, and extend it to 256k. Compared to mainstream Linear Attention approaches, extensive early-stage empirical studies show that SWA is simple, efficient, and practical, delivering stronger overall performance in general tasks, long-context handling, and reasoning. It also provides a fixed-size KV cache, making it easy to integrate with existing training and inference infrastructure.
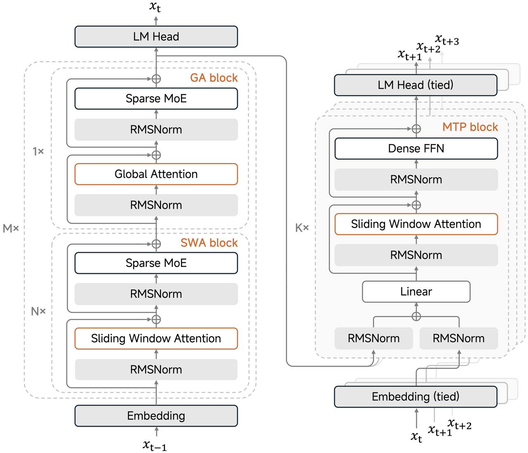
- MTP Inference Acceleration: We introduce MTP (Multi-Token Prediction) to strengthen the model's capability and speed up inference. During inference, MTP validates MTP tokens in parallel, breaking the memory bandwidth bottleneck of traditional decoding under large batch sizes. In practice, a 2.5×–3.7× real-world speedup is achieved with a 3-layer MTP setup.
Related links
-
Technical Report:https://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf
-
Model Weights:https://hf.co/XiaomiMiMo/MiMo-V2-Flash
-
Github Repository:https://github.com/xiaomimimo/MiMo-V2-Flash
-
Blog Post: https://mimo.xiaomi.com/blog/mimo-v2-flash