Xiaomi MiMo-V2.5-TTS-Series + ASR Officially Launched: Your Voice, Under Your Control

Speech technology is undergoing such a transformation: from "being able to listen and read" to "precise understanding and flexible expression". In real creative and interactive scenarios, machines not only need to penetrate complex spoken language environments - dialect accents, environmental noise, multiple people speaking simultaneously - but also use voice to shape characters, grasp emotions, so that expression is no longer just about conveying words, but also conveying feelings.
Whether it's content creators or businesses relying on speech technology, what they truly need is a speech system that can be freely controlled by language: input a noisy meeting recording, and it can accurately transcribe; input a director's note saying "this part should be low and angry", and it can generate a fitting performance. It understands everything and can express everything.
To this end, we officially release today MiMo-V2.5-TTS Series and mimo-v2.5-asr — a whole-link speech model series for the Agent era, covering the two core capabilities of recognition and synthesis, enabling both speech input and output to be freely scheduled by language.
-
The MiMo-V2.5-TTS Series includes three models, which have now been launched on Xiaomi MiMo Open Platform , and are available for free for a limited time . The three models share unified style instruction following, audio label control, and text understanding capabilities, enabling voice performance to be precisely regulated by language, respectively covering three typical creative needs:
-
mimo-v2.5-tts: Built-in with multiple high-quality premium voices, supports fine-grained control over speech rate, emotion, tone, etc., Out Of The Box, meeting multi-scenario expression needs.
-
mimo-v2.5-tts-voicedesign: Quickly define and generate a brand-new voice in one sentence, making voice creation more intuitive and efficient.
-
mimo-v2.5-tts-voiceclone: High-fidelity replication of target timbre with a small number of samples, while maintaining stable style instruction following and audio label control capabilities.
MiMo-Studio Quick Experience Address: https://aistudio.xiaomimimo.com/#/c
- mimo-v2.5-asr is officially open-sourced. The model's speech recognition performance in complex real-world scenarios such as Chinese-English bilingual, Chinese dialects, Code-Switch, strong noise, and multi-speaker has reached the industry-leading level, providing clear and reliable speech transcription for Agents and ensuring that every interaction is based on accurate understanding.
mimo-v2.5-tts: Let Voice Become Everyone's Creativity
Core Features of TTS Series
Precise ability to follow style instructions
From short single-sentence instructions to an entire director's notes, the model can consistently understand and follow them, covering multiple dimensions such as emotion, tone, speaking speed, vocalization style, and language style. Instructions do not need to be written as structured parameters - simply describe the desired feeling as if giving a briefing to an actor, and the model will translate it into the corresponding performance.
For scenarios with higher consistency requirements - such as audio dramas, game NPCs, and character-based dialogues - the model also supports director script-level structured input: characters , scenes , detailed instructions are described in layers, with each layer independently updated at its own pace and freely combined. This layering not only ensures that the timbre identity of the character remains consistent throughout, but also allows the performance of each sentence to be individually controlled.
Case1
Instruct :
声音低沉沙哑一点,像个历经沧桑的老前辈在讲述传奇人物。语气里带点由衷的敬佩,娓娓道来。
Text:
街口那个老周啊,媳妇走得早,一个人拉扯俩娃,白天蹬三轮,晚上还去夜市摆摊修鞋。现在俩孩子都有出息喽,想接他去城里享福——他不去,就守着那间小铺子。哎,人哪,骨头硬,心里头就踏实。
Audio(Voice name:冰糖):
Case2
Instruct :
CHARACTER
曾是守护九天的神祇,见证了凡人的无药可救后,决定以灭世来完成最终的净化。他的心中装满悲悯,但手段是绝对的屠戮。
SCENE
悬浮于崩塌的祭坛之上,俯视下方在火海中哀嚎、曾奉他为信仰的信徒。他在降下最后的毁灭前,发出神圣却残忍的叹息。
DIRECTION
发声机制与共鸣:充分打开胸腔共鸣,制造一种神圣的回音感。声音位置靠后,音色如古钟般低沉且带有金属质感的磁性。
声调与韵律:四声(去声)的下落要极其平缓,不要砸实,带有一种吟诵古籍般的从容与宏大。字句之间的停顿拉长,展现出视万物为刍狗的威压。
气声与实声的较量:在说前两句时,实声饱满,高高在上;但在说出“闭上眼吧”时,声音突然混入大量疲惫的气息,神性开始出现裂痕,流露出勉强的残忍。
咬字细节:古风词汇(如“垂怜”、“沉疴”、“剔骨刮毒”)咬字要深,声母起音圆润而不尖锐。结尾的最后半句,几乎全部转化为气声,像是在哄睡一个婴儿,将残酷包裹在极致的悲哀之中。
Text:
你们求我垂怜,求我降下甘霖洗净这浊世。可这世间的沉疴,唯有烈火能剔骨刮毒。闭上眼吧。这业火烧起来的时候,一点也不疼。
Audio(Voice name:白桦):
Flexible audio tag control capabilities
In addition to paragraph-level natural language instructions, the model also supports inline audio tags, which are used to precisely control emotions, states, or styles at specific positions in the text. The tags support both Chinese and English languages and open text descriptions, allowing flexible mixing within the same paragraph of text. From simple emotional annotations to complex arrangements with multi-tag overlay and fine-grained layout, the model can express stably, demonstrating excellent performance in both the expressiveness of tags and the stability of combinations.
Text:
(调侃) 老张你当时不是说这条航线稳得很吗……
(模仿自信,提高音量) “系统全绿,放心走。”
(突然停顿) ……现在呢?
(爆发,愤怒压不住) 现在整艘船都在报警!你管这叫“放心”?!
(声音变轻) 不过……你看那外面,裂开的星云像在呼吸一样。
(急促|呼喊) 别断通讯!喂!再撑十秒!十秒!!
(低声|情绪塌陷般平静) ……算了。
(轻笑|带点释然) 也挺好,至少是一起看的。
Audio:
Rich text comprehension ability
Even without any prompt or label - just a plain text - the model can directly convey the rhythm and emotion within it. The pauses of punctuation and the undulations of sentence structure will be naturally presented; the emotional arcs hidden in the text, from calm narration to intense twists, can be actively captured by the model; even the speaker's identity (age, temperament, character type) revealed between the lines will automatically be reflected in the voice. In other words: the simplest plain text, when given to it, can still return a vivid and lifelike performance.
Text:
Ten... nine... eight... seven... six... five... four... three... TWO... ONE... ZERO! LAUNCH! LAUNCH! WE HAVE LIFTOFF! GO GO GO! SHE'S CLIMBING! ALTITUDE 1,000... 5,000... 10,000 FEET AND CLIMBING! BEAUTIFUL! AB-SO-LUTE-LY BEAUTIFUL!
Audio:
Model Series
mimo-v2.5-tts
It comes with multiple high-quality voices, covering a variety of usage scenarios. Each voice has been professionally tuned, with natural pronunciation and emotional resonance, allowing you to enjoy high-quality speech synthesis right out of the box. Welcome everyone to visit Xiaomi MiMo Studio for voice previews:
https://aistudio.xiaomimimo.com/#/c
mimo-v2.5-tts-voicedesign
The timbre design is aimed at scenarios where " I have a voice in my heart, but the world doesn't have one yet ": game NPCs, animated characters, virtual LIVE creators, brand IPs, atypical voices of audio dramas - these are difficult to choose directly from the timbre library and are not suitable for human cloning.
This model supports generating a brand new timbre from scratch through natural language descriptions , without the need for any reference audio. Users can freely use any descriptive dimensions such as age, gender, accent, timbre, vocalization style, personality, etc. - for example, "an elderly Eastern European scholar, with a deep, slightly hoarse voice and a slow speaking rhythm" or "a vibrant young girl, with a clear voice and a slight upward inflection at the end of sentences" - and the model can synthesize the corresponding character timbre.
Thanks to large-scale pre-training, the model can also reasonably interpret complex, ambiguous, or even contradictory descriptions, rather than being limited to coarse-grained labels such as "male/female/young/old". This enables timbre design not only to generate unique voices that are difficult for real people to provide, but also to accurately reproduce the voice lines of a certain type of character.
Case1
Instruct :
一位中年男性,说标准普通话,嗓音低沉有磁性,带有轻微的沙哑质感,像纪录片旁白解说员,沉稳而有感染力。
Text:
当最后一缕阳光消失在地平线之下,这片沉睡了亿万年的大地开始显露它真正的面貌。在这寂静的荒野中,每一块岩石都记录着时间的流逝,每一阵风都在诉说着古老的故事。
Audio:
Case2
Instruct :
一位年迈的老先生,说带北方口音的普通话,语速缓慢而沉稳,嗓音略带沙哑和沧桑感,仿佛一位饱经风霜的老爷爷在讲故事,充满岁月的智慧。
Text:
我这辈子啊,走南闯北六十多年。见过最热闹的集市,也见过最安静的戈壁。到头来才明白一个道理——这人哪,不在走了多远的路,在于记住了多少风景。年轻人,别光顾着赶路,偶尔也停下来看看天。
Audio:
mimo-v2.5-tts-voiceclone
Voice cloning is used to enable the model to speak in the voice you specify—replicating a real-life podcaster, voice actor, brand spokesperson, or the user themselves.
Simply provide a reference audio as short as a few seconds , and without any additional training, annotation, or fine-tuning process, the model can directly reproduce the speaker's timbre and be immediately available. The reproduced voice not only retains the timbre identity of the original speaker but also preserves personal characteristics such as breath, rhythm, and habitual pauses.
The cloned timbre can reuse all the control capabilities of this series of models — natural language instructions, audio tags, and director-level scripts can all continue to be used in combination. The reproduced voice not only "sounds like the original person" but can also perform according to the style and emotion you specify.
Prompt:
Instruct:
用尖锐刻薄的嗓音,带着狐假虎威的得意感说话,在提到大人物的身份时故意放慢语速并加重语气,营造压迫感。
Text:
你以为我是谁,也敢在这儿跟我耍横?我告诉你,站在我身后的那个人,说出来吓死你——是当今的——万岁爷!你今天要是不给我个说法,我让你这铺子明天就开不了门。
Audio:
mimo-v2.5-asr: Understand every expression of yours, no matter how complex
If TTS enables voice to become a creative tool at the "output" end, then ASR opens the door to all this at the "input" end. In real-world scenarios, being able to clearly and accurately understand speech amidst language switching, background noise, and speakers with strong dialect accents is what truly makes a good speech recognition system.
mimo-v2.5-asr, as the auditory foundation of the whole-link speech model series, has achieved industry-leading levels in complex real-world scenarios such as Chinese-English bilingual, Chinese dialects, Code-Switch, strong noise, multi-speaker, and high knowledge density. It is not just about converting clear speech into text, but also enabling agents to capture every word and phrase worthy of understanding in noisy real-world sounds.
Core Features
Chinese dialects: Supports dialects such as Wu dialect, Cantonese, Minnan dialect, Sichuan dialect, etc.
Complex English Scenarios: Achieved leading performance on the Open ASR Leaderboard in complex English scenarios such as AMI
Code-Switch: Free and smooth speech transcription for Chinese-English Code-Switch, no need to pre-set language labels
Song Recognition: Recognizes lyrics of Chinese and English songs, maintaining high accuracy in scenarios where accompaniment and vocals are mixed
Strong noise scenario: Maintains robust recognition in complex acoustic environments such as high noise and far-field sound pickup
Multi-speaker: Supports accurate transcription of multi-person cross-dialogue scenarios, such as meeting scenarios
Strong Knowledge Association: Precise identification of knowledge-intensive content such as ancient poems, technical terms, personal names, and place names
Native Punctuation: Outputs punctuation natively by combining speech prosody and semantics, with the transcription results ready for immediate use without post-processing
Performance
mimo-v2.5-asr has achieved the current optimal or highly competitive results across multiple dimensions, including general Chinese and English, Chinese dialects, Code-Switch, and lyrics recognition, demonstrating its stable advantages across scenarios and languages. The following are representative evaluation results:
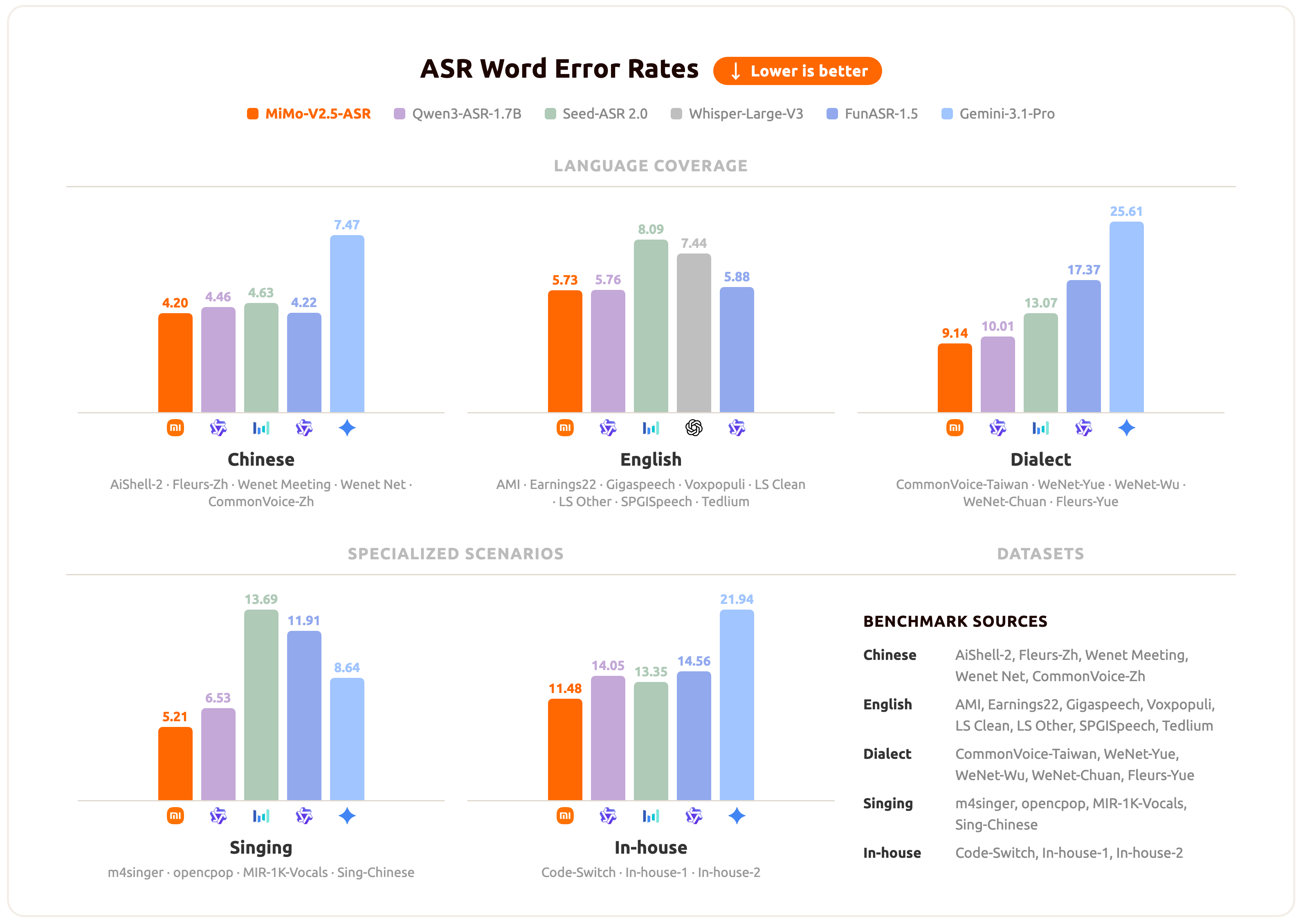
For Agent applications, content creation tools, conferencing systems, and voice interaction products, this is a truly verified auditory foundation in complex real-world speech.
How to Use
MiMo-V2.5-TTS Series
To assist developers in exploring more scenarios,mimo-v2.5-tts, mimo-v2.5-tts-voicedesign, and mimo-v2.5-tts-voiceclone are all available for free on the Xiaomi MiMo API Open Platform for a limited time: https://platform.xiaomimimo.com/docs/usage-guide/speech-synthesis-v2.5
Meanwhile, everyone is welcome to visit Xiaomi MiMo Studio for a quick experience:https://aistudio.xiaomimimo.com/#/c
For more cases, please refer to https://mimo.xiaomi.com/mimo-v2-5-tts
mimo-v2.5-asr
mimo-v2.5-asr has now open-sourced its model weights and code, enabling developers and researchers to directly use or conduct secondary development.
Demo page: https://mimo.xiaomi.com/mimo-v2-5-asr
Project Open Source Address: https://github.com/XiaomiMiMo/MiMo-V2.5-ASR
Weight Open Source Address: https://huggingface.co/XiaomiMiMo/MiMo-V2.5-ASR
Huggingface space: https://huggingface.co/spaces/XiaomiMiMo/MiMo-V2.5-ASR
Agent Tool Call Support
To facilitate everyone's quick integration of speech capabilities into Agent applications, we have fully open-sourced the access Skill for mimo-v2.5-tts related models. Welcome to visit the repository to pull and use:
https://github.com/XiaomiMiMo/MiMo-Skills
Sound is just the starting point
Beyond the MiMo-V2.5-TTS Series, we would like to answer a question:
What will audio creation look like when mimo-v2.5-tts understands "expression", mimo-v2.5-pro understands "planning", and mimo-v2.5 understands "listening"?
The answer is: a complete, closed-loop Agent-style creative chain.
-
mimo-v2.5-pro —— Planning and screenwriting, breaking down tasks, writing scripts, arranging rhythm, and determining the editing sequence.
-
MiMo-V2.5-TTS Series —— Timbre and Creatives, Voice Design generates timbre, Voice Clone synthesizes content.
-
mimo-v2.5 —— Listening back and evaluation, checking if the character is consistent, if the rhythm is correct, and if it deviates from the user's original intention.
An example:
Create a scene of a summer afternoon lasting about 2 minutes. Grandpa (in his 70s, with a Beijing hutong accent, hoarse voice, drawn-out speech, lowered voice when concentrating on chess, and a booming laugh with a table slap) is playing chess under a pagoda tree. A 5-year-old grandson is squatting beside, watching ants, and occasionally interrupting with childish questions (clear, with rising intonation at the end, higher when excited, and occasional unclear pronunciation). Grandpa's tone is solemn when he gets serious, but immediately softens into a laughing scold when interrupted by his grandson.
Users only provide a single sentence, and the finished product is generated automatically:
Some may say it's a threshold, but being able to listen, think, and collaborate is what truly matters.
Next step
-
Larger-scale speech pre-training and post-training with reinforcement learning: MiMo-V2.5-TTS-Series demonstrates the significant benefits of large-scale pre-training and post-training, expanding the scale of both: through more data, larger models, and stronger computing power, enabling more powerful speech intelligence to emerge from scale; more refined reward modeling and reinforcement learning algorithms drive the model towards higher-order speech expression intelligence.
-
Universal Audio Generation: Speech is just the first step. We are expanding our capabilities to more generalized audio generation: environmental sound effects, action sounds, ambient backgrounds, and even short musical phrases and melody segments—gradually modeling a complete sonic world. We believe that a true universal audio model is not simply piecing together speech, sound effects, and music, but enabling them to understand each other and collaborate in the same space.
-
Contextual understanding ability: Speech expression has never been an isolated sentence game. The reason people can "read correctly" is because they understand the context—knowing what happened before and understanding where the current sentence fits into the overall narrative. Contextual understanding means that the model is no longer just a "tool for executing sentences one by one," but an expresser who understands the context of the story. This is a crucial step towards truly general speech intelligence.
-
General Speech Understanding Ability: Our goal is to ensure that "real-world norms" such as dialects, noise, and Chinese-English mixtures no longer become the weak points of speech recognition. In the future, we will continue to expand the coverage of more dialects and deepen context awareness capabilities, enabling speech recognition to evolve from "transcription" to "understanding".
