Xiaomi MiMo-V2-Omni: Omni-Modal Agentic Foundation Model that Sees, Understands and Acts
Today, we are thrilled to announce Xiaomi’s omni‑modal foundation model for agent era: Xiaomi mimo-v2-omni.
Designed specifically for complex real‑world multimodal interaction and execution scenarios, mimo-v2-omni is built from the ground up as a unified all‑modal foundation that integrates text, vision, and speech. Its unified architecture deeply binds perception and action, overcoming the traditional limitation of models that prioritize understanding over execution.
Natively equipped with multimodal perception, tool invocation, function execution, and GUI operation capabilities, mimo-v2-omni seamlessly integrates with major agent frameworks. It enables a true leap from understanding to control, drastically lowering the barrier to deploying all‑modal agents.
Perception Capabilities: Image, Video, and Audio on the Frontier
Accurate perception is the prerequisite for action. We benchmarked mimo-v2-omni against leading international models across all sensory modalities to ensure a rock-solid foundation for its capabilities as an AI agent.
Visual Understanding: mimo-v2-omni demonstrates robust multidisciplinary visual reasoning and complex chart analysis. It has surpassed Claude 4.6 Opus and is rapidly closing the gap with top-tier closed-source models like Gemini 3.
Audio Understanding: The model supports everything from environmental sound classification and multi-speaker separation to audio-visual joint reasoning and deep comprehension of continuous audio exceeding 10 hours. Its comprehensive performance exceeds Gemini 3 Pro, making it one of the most powerful audio understanding base models currently available.
Video Understanding: By supporting native audio-video joint input, we have achieved true multimodal video comprehension. Through innovative video pre-training, the model possesses powerful situational awareness and predictive reasoning capabilities.
When multiple modalities are processed simultaneously, the advantages of a unified architecture are magnified: cross-modal signals mutually reinforce one another rather than competing for resources.
Agentic Capabilities: from Understanding to Execution
If perception is the foundation, then action is the ultimate goal.
A true AI agent model must be capable of observing complex environments across multiple modalities, formulating and executing plans, autonomously recovering from errors, and delivering end-to-end results.
Omni-Modal Agent Tasks
mimo-v2-omni excels in benchmarks involving interaction with real-world digital environments, performing on par with Gemini 3 Pro. This success is underpinned by its industry-leading perceptual capabilities:The more accurate the perception, the more effective execution.
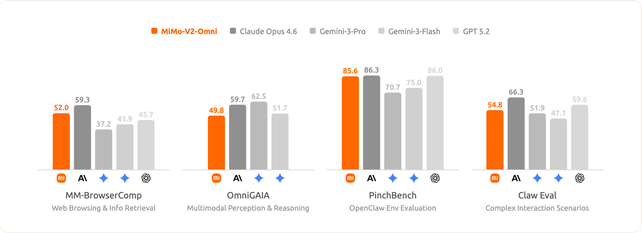
At the same time, mimo-v2-omni remains highly competitive in text-only agent tasks.
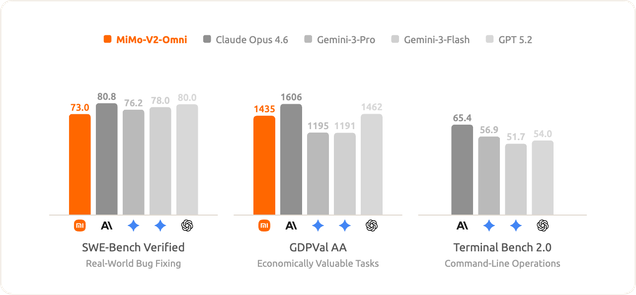
Capabilities Demonstration
💻 Browser-Use Scenarios
Browser Use is the ultimate litmus test for a model’s agentic capabilities. It involves real-world interactions, dynamic web environments, heterogeneous interaction methods, and active anti-automation mechanisms. In these scenarios, the closed loop of perception, decision-making, and action operates continuously in an open environment until the mission is accomplished. When these same capabilities are ported to smart devices or robotics, they form the blueprint for General-Purpose Agents.
-
Shopping, Bargaining, and Ordering on Your Behalf
We tested an end-to-end shopping task. Controlling the browser, the model first browsed over a dozen posts on Xiaohongshu to complete information gathering and obtain purchasing recommendations. It then performed cross-platform price comparisons across multiple stores on JD, followed by connecting with human customer service to bargain using natural language. After real-time interaction with the representative, it ultimately completed the process of adding items to the cart and placing the order. The model autonomously handled non-standard DOM structures, multi-tab context management, and workflow recovery after encountering platform anti-automation detections.
-
TikTok Video Creation and Publishing
We tested an end-to-end video publishing task. The model autonomously designed four sets of visuals and synthesized all sound effects on-site with zero reliance on external assets. During rendering, it encountered a Chinese font error, which it self-corrected before continuing. It then controlled the browser to open the TikTok upload page, analyzed non-standard input controls to complete the copywriting, and proceeded to like and comment after clicking "Publish." Finally, it re-checked to confirm the video passed review and was publicly live.
🗒️ Smart Office Scenarios
Through natural dialogue, mimo-v2-omni can directly generate high-quality Word documents, structured Excel sheets, professionally formatted PDFs, and complete PPTs. These generated documents are no longer drafts requiring heavy revision, but high-quality "near-final versions" tailored to actual needs.
-
2026 Intelligent College Entrance Examination Application
We tested the college entrance examination application planning task. The model can autonomously initiate web searches to obtain raw information, use skills to process files, and generate an Excel spreadsheet containing detailed application recommendations and tiered classifications.
Open API
The mimo-v2-omni model is now officially available via API with pricing:
-
Input: $0.4 / million tokens;
-
Output: $2 / million tokens.
Visit https://platform.xiaomimimo.com to get started.